 |
nedoPC.orgElectronics hobbyists community established in 2002 |
 |
| Atom Feed | View unanswered posts | View active topics |
It is currently 21 May 2024 09:13 |
|
All times are UTC - 8 hours [ DST ] |
Самодельный процессор nedoRISC-0 (NEDONAND)
Moderator: Shaos
|
|
Page 9 of 13 |
[ 193 posts ] | Go to page Previous 1 ... 6, 7, 8, 9, 10, 11, 12, 13 Next |
| Previous topic | Next topic |
Самодельный процессор nedoRISC-0 (NEDONAND)
| Author | Message | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Admin  Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Купил на ебее платку для монтажа накруткой - чуть меньше чем за сотню с доставкой
 14 рядов по 136 золотых контактов в каждом, плюс периодически расставленные ноги земли и питания, плюс разъём 36x3 контактов! Если ставить туда 74F00, оставляя место под конденсатор (т.е. 8 пар ног занимать на микросхему), то в эту плату влезет 119 микросхем... P.S. Хотя наверное крупновата платка для этой конкретной задачи - на ней надо что-то типа такого собирать... |
||||||||||||||||||||||||||||||||||||
| 02 Mar 2016 18:29 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Пришли платки:  Собрал пока лишь для 4 байтов т.к. однорядных сокетов таких (для втыкания диодов) у меня больше нет (надо заказывать):  Щас примусь за тестирование... |
||||||||||||||||||||||||||||||||||||
| 03 Mar 2016 20:49 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Подключил к 7-сегментному индикатору и закодировал числа 0,1,2,3 - работает
 |
||||||||||||||||||||||||||||||||||||
| 04 Mar 2016 17:06 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Вот думаю а не спаять ли из одной такой платки вечный декодер из 4 битов в 7-сегментный индикатор для показа HEX?
Вечный в том смысле, что диоды будут намертво припаяны - чисто для демонстрации P.S. Более того - индикатор можно прямо в плату воткнуть (скажем в правый-нижний угол) |
||||||||||||||||||||||||||||||||||||
| 06 Mar 2016 00:55 |
|
||||||||||||||||||||||||||||||||||||
|
Supreme God  Joined: 21 Oct 2009 08:08 Posts: 7777 Location: Россия |
В каком-то древнем журнале "Радио" в разделе "Обмен опытом" предлагали схемку на обычном дешифраторе типа "код-позиция", дополненным диодным дешифратором, как раз для тех, у кого нет специфических дешифраторов для 7-сегментного индикатора. Помню, мы с другом на 5-м курсе сочиняли такой диодный дешифратор сами, в спешке, "в лоб" и с матюками, ибо время подпирало... Долго хранил тот листочек, если подобное повторится, а потом и статью в "Радио" как-то нашел. Было даже слегка обидно:"если бы мы знали, мы бы так не тужились!" _________________ iLavr |
||||||||||||||||||||||||||||||||||||
| 06 Mar 2016 03:39 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Собрал платку-индикатор из NEDONAND-16 и обнаружил, что в этом экземпляре платки есть косяк - дорожка прилипла к паду у одной из земляных ног микросхем с правой стороны платы - в результате на одном из выходов всегда "0" - подрезал дорожку, однако в собранном прошлый раз экземляре платки оно не коротило - видимо таки надо платку переразвести чуток, чтобы оно не залипало при производстве будущих экземпляров...
P.S. Вот думаю как делать в "недонанде" индикацию адреса и опкода - на нескольких таких платках (по одной на каждый шестнадцатиричный разряд) или на одной такой платке плюс мультиплексоры-демультиплексоры, чтобы по циклу переподключать её к разным 7-сегментным индикаторам? |
||||||||||||||||||||||||||||||||||||
| 07 Mar 2016 08:46 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Пришли "неправильные" платки NEDONAND-4, немного подковырял как предполагалось выше:   Собрал тестовый "стэнд" для втыкания в него nedoCPU-16:  Только наверное скорость особо 20-мегагерцовым пиком не померять т.к. он только 5 миллионов команд в секунду делает (это 200 нс)... P.S. Думал было на SX-28 нагородить что-то (он может 80 МГц гнать со скоростью одна команда на такт), но потом мне сообщили, что есть такой LogicPirate, который снимает логические осциллограммы прямо в SPI SRAM-ы на частотах до 80 МГц http://dangerousprototypes.com/docs/Logic_Pirate Так что наверное для анализа скорострельности я буду аналогичный подход использовать... |
||||||||||||||||||||||||||||||||||||
| 09 Mar 2016 19:45 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Выпаял четыре микросхемы пока не нашёл вторую залипшую дорожку...   Собрал вместе NEDONAND-3 с двумя NEDONAND-2 плюс NEDONAND-16 с "прошивкой" декодера из 4 битов в шестнадцатиричную цифру:  Видео: https://youtu.be/JhHOd0FVcaM |
||||||||||||||||||||||||||||||||||||
| 09 Mar 2016 22:44 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Вот интересная статейка про реверснутый АЛУ из 8085 - оказывается вместо сдвига влево он использовал сложение аргумента с самим собой
http://www.righto.com/2013/01/inside-alu-of-8085-microprocessor.html А вот тут объясняется как работает флаг overflow в реверснутом 6502: http://www.righto.com/2013/01/a-small-part-of-6502-chip-explained.html
Что есть тоже самое как и C6 xor C7 (исключающее или между переносами из последнего и предпоследнего битов - я проверил):
|
||||||||||||||||||||||||||||||||||||
| 11 Mar 2016 05:39 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Одновременно пришли все оставшиеся платки, заказанные в период с 26 февраля по 1 марта:
 т.е. производство длилось от 10 до 15 дней... |
||||||||||||||||||||||||||||||||||||
| 11 Mar 2016 20:26 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Не нравятся мне эти дырки между операциями ALU и копированием аккумулятора куда-то. В-принципе, проц может распознать, что следом за командой, требующей ALU, идёт копирование из аккумулятора, и в результате проц может изменить поведение этой команды копирования, чтобы копировать НЕ аккумулятор, а результат работы ALU ! Причём результат ALU надо записать одновременно в 2 регистра - в регистра аккумулятора и в регистр куда аккумулятор скопировали - по идее должно срастись... |
||||||||||||||||||||||||||||||||||||
| 12 Mar 2016 20:20 |
|
||||||||||||||||||||||||||||||||||||
|
Writer
Joined: 19 May 2014 03:47 Posts: 17 Location: Челябинск |
Может я уже поздно, но вы сами меня банили, так что не обессудьте.
Хотел бы вас предостеречь от строительства процев на рассыпухи НИЗКОЙ разрядности. Несмотря на кажущуюся экономию ресурсов и времени, подобные проекты оборачиваются излишней сложностью декодирования команд, невозможностью расширения и низкой скоростью выполнения команд - проще сделать последовательный многоразрядный процессор, чем узкий параллельный. Подобный вывод можно проследить также в быстром укрупнение разрядности у всех крупных производителей процессоров, которые за 10 лет перешли от 1 и 4 разрядных секций к 8 и 16 разрядным, полноценным процессорам (1968-1978). И далее не остановились на этом. Оптимальным для человеческого проектирования (без участия в создании разводки кристалла CAD и компьютеров) и программирования, особенно для риск-архитектуры, является как раз 32-битная архитектура. Но она сама по себе является затратной. Для домашнего же проектирования риск-проца оптимальным является 16-ти битный формат. К такому выводу также пришёл известный блоггер Хабра, который и рассказал мне об этом. В чём оптимальность? - прямая адресация регистров проца (особенно в 32 битном формате), без необходимости строить дешифраторы (3 в 8 или 4 в 16) на простой логике, прямая кодировка команд в битах кода операции (32-й бит - это сложение, 31 бит - это вычитание, 30-й бит это ИЛИ, 29-й бит это И и т.д.), Отсутствие дешифраторов ускоряет весь проц, устраняет задержки на считывание, оставляет возможность модернизации системы команд без полной реорганизации и переделки внутренней схемотехники проца. Также становится выгодным делать версии проца на последовательной шине, что конечно замедляет проц, но и сильно удешевляет его демо-вариант. Евген. |
||||||||||||||||||||||||||||||||||||
| 13 Mar 2016 02:42 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
Ну с одной стороны так оно, а с другой расходование пространства опкодов на побитное кодирование оперций выглядит излишне расточительно...
|
||||||||||||||||||||||||||||||||||||
| 13 Mar 2016 05:11 |
|
||||||||||||||||||||||||||||||||||||
|
Writer
Joined: 19 May 2014 03:47 Posts: 17 Location: Челябинск |
16 бит - 64 тыщи кодов. 32 бита - даже считать не охота. Но эта конечно для кодированных опкодов. А для расшитых, т.е. прямых микрокодов, где каждый разряд отвечает за одно действие, конечно поменьше останется, в миллион раз.... Ну скажем примем что это самодельный проц и разбегаться не будем: скажем 8 общих регистров - это займёт 16 бит в опкоде для указания источника и приёмника. 4 разряда на булеву алгебру, 4 на сдвиги и арифметику (влево, вправо, сложение, сравнение) и 4 на переходы. 4 останется ещё на что нибудь (резерв, может быть прерывания). Итого 64 комбинации с каждым регистром на каждое действие, включая переходы. 12х64 = 768 опкодов (включая бесполезные). Ещё останется 4 разряда. |
||||||||||||||||||||||||||||||||||||
| 13 Mar 2016 06:27 |
|
||||||||||||||||||||||||||||||||||||
|
Admin Joined: 08 Jan 2003 23:22 Posts: 22757 Location: Silicon Valley |
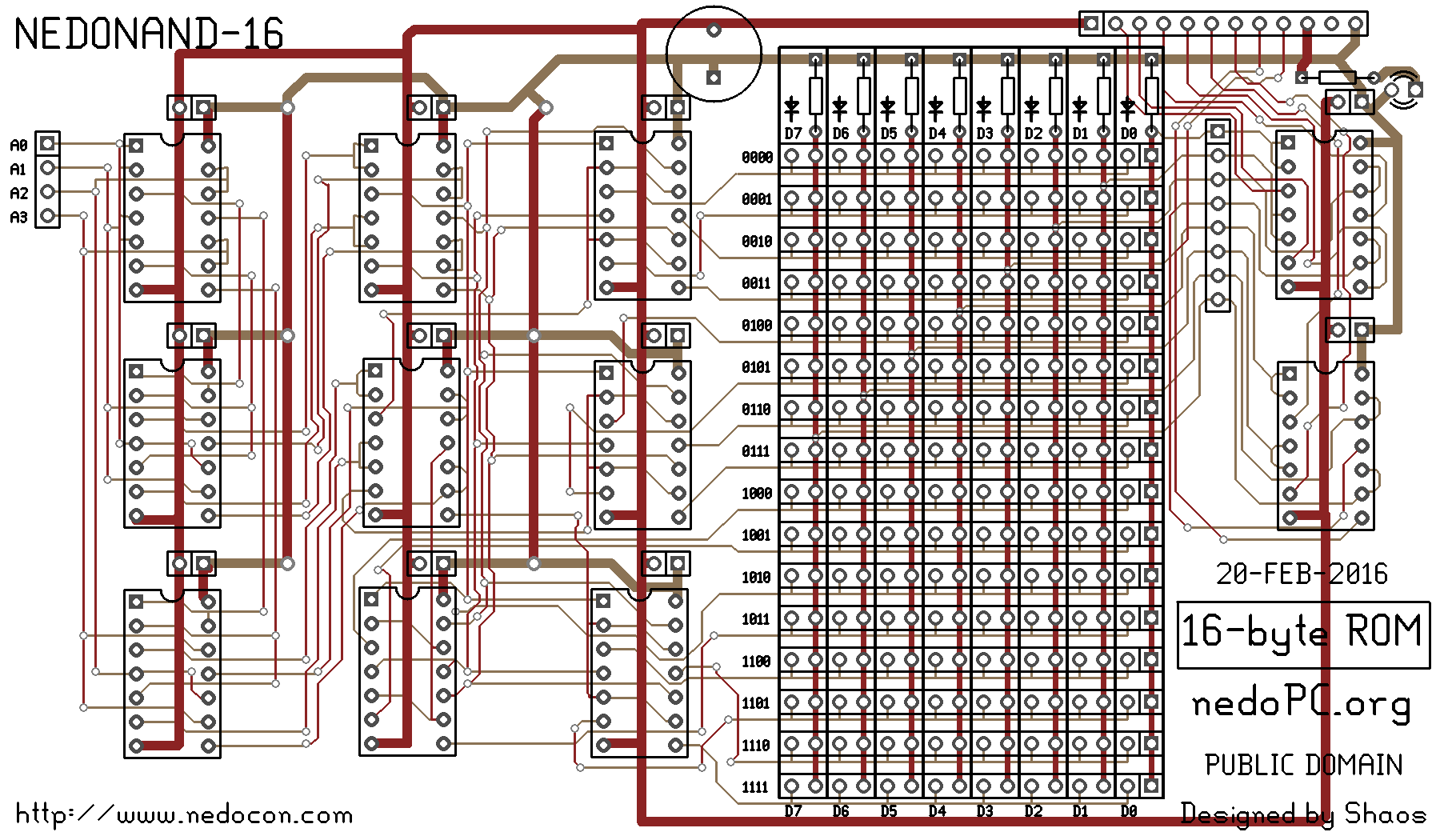
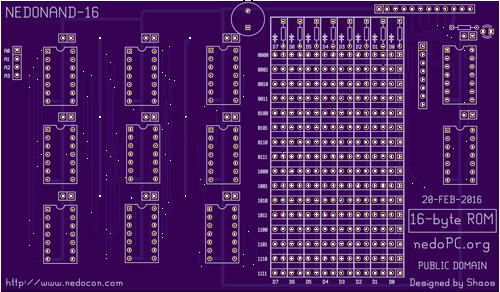
|
||||||||||||||||||||||||||||||||||||
| 14 Mar 2016 07:35 |
|
||||||||||||||||||||||||||||||||||||
|
|
Page 9 of 13 |
[ 193 posts ] | Go to page Previous 1 ... 6, 7, 8, 9, 10, 11, 12, 13 Next |
|
All times are UTC - 8 hours [ DST ] |
Who is online |
Users browsing this forum: No registered users and 5 guests |
| You cannot post new topics in this forum You cannot reply to topics in this forum You cannot edit your posts in this forum You cannot delete your posts in this forum You cannot post attachments in this forum |
