если использовать основное АЛУ (да ещё и 1 битное или с последовательным переносом) то.... 32-128 тактов на вычисление реального адреса....
придется мудрить со специальным, но 32-битный сумматор считающий, если по максимуму, [адрес начала сегмента]+[начало блока данных внутри сегмента]+[индекс]+[сравнение с адресом конца сегмента] ну и может ещё что, пока в голову не приходит
вообщем это похоже будет очень долго
____________________________________________________
можно немного схитрить, объявить внешнюю шину адреса 24бит и сделать сегментирование по границам 256 байт (минус последних 8 бит), тогда складывать придется только 16бит
при использовании микросхемы 555ИМ6 (SN74LS283) получится 24нс * 4 = 96нс по времени должно укладываться в 1 такт на 10МГц
хм... может что и выйдет
самодельный многозадачный процессор
Moderator: Shaos
-
pfgx
- Senior
- Posts: 137
- Joined: 20 Mar 2013 03:36
- Location: Ростов-на-Дону
Не-е, я это рисовать не буду, мне Z80 достаточноMogrif wrote:fpga это не спортивно, а вот 80386 не отказался бы посмотреть схемку на предмет реализации защиты памяти и выгрузки состояния процессора при переключении процесса
А почему нет? Там же транзисторы никто не считает. А в защищённом режиме ещё и преобразование по таблице сегментов происходит, которая вроде как в памяти при этом находится, но на самом деле видимо кэшируется.Mogrif wrote:опять же интересно как в х86 вычисляется реальный адрес, при адресации через сегмент:смещение, при адресации через набор регистров (базовая косвенная адресация)
не может же там тупо стоять сумматор
-
Mogrif
- Writer
- Posts: 23
- Joined: 27 Feb 2014 05:15
- Location: 93.123.183.154
никаких сегментов в памяти, вернее там они конечно будут, но для вычисления адресов будут специальные системные регистры (пока 2 шт) с адресами сегментов программы и данныхpfgx wrote:А в защищённом режиме ещё и преобразование по таблице сегментов происходит, которая вроде как в памяти при этом находится, но на самом деле видимо кэшируется.
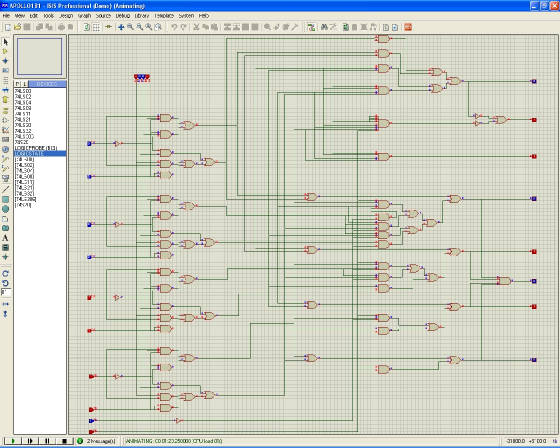
в протезусе нет чипа 74182, печаль
-
Stan

- Banned
- Posts: 397
- Joined: 04 Jan 2013 10:09
- Location: 95.24.178.158
74181 - тоже не было, но можно выйти из положения с помощью "подсхемы", как вот этот итальянский автор Gianluca G.Mogrif wrote:в протезусе нет чипа 74182, печаль
-
Mogrif
- Writer
- Posts: 23
- Joined: 27 Feb 2014 05:15
- Location: 93.123.183.154
можно и подсхему нарисовать, только она будет симулироваться не как отдельный чип со своими характеристиками, а как набор рассыпной логики и, например, тайминги я уже просимулировать не смогу
в справочнике время срабатывания написано покаскадно, и непонятно какое время пройдет от получения команды до выхода полного результата у комплекта 4хИП3+ИП4
в справочнике время срабатывания написано покаскадно, и непонятно какое время пройдет от получения команды до выхода полного результата у комплекта 4хИП3+ИП4
-
Stan
- Banned
- Posts: 397
- Joined: 04 Jan 2013 10:09
- Location: 95.24.178.158
-
Mogrif
- Writer
- Posts: 23
- Joined: 27 Feb 2014 05:15
- Location: 93.123.183.154
с протезусом не до конца ещё разобрался, может и смогу собрать правильную схему
но вот с уже столкнулся с тем, что схема ИП4 из Шило и 74182 из даташита не совпадают. надо сидеть и сравнивать по табличным значениям.
а хотелось бы общее АЛУ на 4хИП3+ИП4 и им же считать адреса, если эта схема способна уложиться в 1 такт приемлемой частоты, а лучше чтобы этим же тактом шел запрос к памяти (не факт что получится)
я правильно думаю что адрес на шине уже должен быть, перед любым обращением к памяти?
но вот с уже столкнулся с тем, что схема ИП4 из Шило и 74182 из даташита не совпадают. надо сидеть и сравнивать по табличным значениям.
а хотелось бы общее АЛУ на 4хИП3+ИП4 и им же считать адреса, если эта схема способна уложиться в 1 такт приемлемой частоты, а лучше чтобы этим же тактом шел запрос к памяти (не факт что получится)
я правильно думаю что адрес на шине уже должен быть, перед любым обращением к памяти?
-
petrenko
- Doomed
- Posts: 598
- Joined: 10 Mar 2012 16:21
- Location: РФ
-
Mogrif
- Writer
- Posts: 23
- Joined: 27 Feb 2014 05:15
- Location: 93.123.183.154
-
Mogrif
- Writer
- Posts: 23
- Joined: 27 Feb 2014 05:15
- Location: 93.123.183.154
помедитировал над схемами ИП3 и ИП4 и понял что это схема с хоть и ускоренным но все-таки последовательным переносом, так что скорость выполнения 16-битного сложения будет 4*ИП3 + 3*ИП4 , что для вычисления адреса неприемлемо, а жаль
значит будет пока на ИМ6:
итого получаем 3*17+24 = 74нс
если я не ошибаюсь 1 такт на 10МГц составляет 100нс
значит будет пока на ИМ6:
надеюсь хоть это правильноСумматор К555ИМ6
время задержки распространения сигнала от входов до выходов суммы составляет 24нс (до выходов переноса Сn+1 не более 17нс
итого получаем 3*17+24 = 74нс
если я не ошибаюсь 1 такт на 10МГц составляет 100нс
-
Mixa64

- Doomed
- Posts: 509
- Joined: 25 Aug 2009 07:02
- Location: Москва
-
MM

- Banned
- Posts: 102
- Joined: 02 Feb 2014 08:29
- Location: Павловский Посад
Не знаю, насколько будет по-спортивному предложить одно интересное решение - вместо хитрющей логики поставить простое ПЗУ, да побольше объемом - так поступали в узкоспециализированных БЦВМ при коммунизме.
Пример : имеется задача за 200 нс перемножить 2 шт. 8-битных числа.
Решение : ставим 128 кбайт ПЗУ - на входы адреса подаётся 1-е число - 8 бит и 2-е число - 8 бит. На выходе - 16 бит ответ. Для использования 573РФ4 получалась полная плата размера корзинки ДВК.
Так же можно поступить и с некотрыми специфическими функциями.
Если совсем кратко - с использованием 530-й серии и 9-слотовой корзинки от Э-60 получалась производительность процессора - не менее 1 флопс - в 1988 г.
*
ИМХО - если расписывать процессор по конвееру - для скромного 16-бит решения запросто можно потратить месяцы или даже годы.
*
Правда, уже в 1992 г. стали применять J11-15 мгц, он сопоставим по производительности с приведенным примером, и на полпорядка компактнее.
*
Припоминаю, была попытка сделать многоплатное решение с использованием массива ОЗУшек - статики, в который прописывалось задание пользователя ( точнее, развесистый микрокод пользователя), но дальше исследовательской работы это не пошло.
Пример : имеется задача за 200 нс перемножить 2 шт. 8-битных числа.
Решение : ставим 128 кбайт ПЗУ - на входы адреса подаётся 1-е число - 8 бит и 2-е число - 8 бит. На выходе - 16 бит ответ. Для использования 573РФ4 получалась полная плата размера корзинки ДВК.
Так же можно поступить и с некотрыми специфическими функциями.
Если совсем кратко - с использованием 530-й серии и 9-слотовой корзинки от Э-60 получалась производительность процессора - не менее 1 флопс - в 1988 г.
*
ИМХО - если расписывать процессор по конвееру - для скромного 16-бит решения запросто можно потратить месяцы или даже годы.
*
Правда, уже в 1992 г. стали применять J11-15 мгц, он сопоставим по производительности с приведенным примером, и на полпорядка компактнее.
*
Припоминаю, была попытка сделать многоплатное решение с использованием массива ОЗУшек - статики, в который прописывалось задание пользователя ( точнее, развесистый микрокод пользователя), но дальше исследовательской работы это не пошло.
-
Shaos

- Admin
- Posts: 24637
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
-
petrenko
- Doomed
- Posts: 598
- Joined: 10 Mar 2012 16:21
- Location: РФ
Уж не обессудьте, коллега, но решение не самое рациональное..Пример : имеется задача за 200 нс перемножить 2 шт. 8-битных числа.
Решение : ставим 128 кбайт ПЗУ - на входы адреса подаётся 1-е число - 8 бит и 2-е число - 8 бит. На выходе - 16 бит ответ. Для использования 573РФ4 получалась полная плата размера корзинки ДВК.
Я ещё учась в школе запросто перемножал два двоичных 12-битных без-знаковых числа за те же 200нс при помощи ПЗУ-шек организованных как 8192*24 и ещё четырёх ИМС средней степени интеграции ( в "нашем" смысле средней - в "буржуинском" они считаются мелкой логикой )
( Не подумайте никоим образом, что хвастаю, ибо кроме меня так же умели делать, пожалуй, не менее десятка тысяч советских инженеров - дело то сие вполне заурядное, если школьные формулы знать... )
Кто Вам такое сказал, коллега ?если расписывать процессор по конвееру - для скромного 16-бит решения запросто можно потратить месяцы или даже годы.
Уж не "британские учоные" часом ?
Не верьте им.
Как же 165гф2 тактировала процессоры серии 145ик ?(риторический)
Советские разработчики потратили на проектирование отнюдь не 15 и не 10 лет.......
И, кстати, неважно, "скромные" 16 бит или "роскошные" 128 бит - многофазное управление процессом будет совершенно одинаковое.
-
MM
- Banned
- Posts: 102
- Joined: 02 Feb 2014 08:29
- Location: Павловский Посад
Насчет "расписывать процессор по конвееру" - это гораздо более сложный процесс я упомянул, следует понимать как "при максимальной тактовой частоте логики" - т.е. фазное управление в принципе не рассматривается. Реально это фантастически сложный процесс - Интел его делала усилием десятка яйцеголовых ручками за 2-3 года на камешек. Однако, результат - на максимальной ( тактовой ) частоте конвееризованный процессор показывает не менее, чем 2-х кратный прирост на классических смесях команд ( при линейной подаче команд - соответственно степени конвееризации ).
Первым конвеерным был 486 - но я могу ошибаться. Не конвеерным был 386DX - 7 тактов на рег-рег.
Апофеоз одноядерности в Интел - 8-параллельный Т(итаниум) - до 3-х подряд идущих ветвлений без потери крейсерской скорости - думается, со временем и господа из Израиля сцапают этот рецепт ( разработчики Коре-дуля ).
*
Насчет хитрости с экономией ПЗУ - не я разработчик, я просто привел пример - не стоит упускать из внимания, что готово было в 1988 г. - т.е. начали свистать с оригинала году так в 1983. К тому же я привел законченный вариант - 200 нс РФка - её не обойти ( напрямую ).
Были, конечно, и масочные ТТЛШ ПЗУ - с временами менее 60 нс,
но мне такие конструктивы не извесны ( т.е. готовые умножители 12 бит ).
*
Вот клянчил у Ю.Л. Отрохова ТО на его камень 1013ВМ1 - хрен дал
( официально ). И даже не счел нужным ( он ) упомянуть, что полно камушков без "К" - по этому и не дает ТО ( официально ) :
http://forum.ixbt.com/topic.cgi?id=64:3394-153 ( Иванов И.И. = MM )
Первым конвеерным был 486 - но я могу ошибаться. Не конвеерным был 386DX - 7 тактов на рег-рег.
Апофеоз одноядерности в Интел - 8-параллельный Т(итаниум) - до 3-х подряд идущих ветвлений без потери крейсерской скорости - думается, со временем и господа из Израиля сцапают этот рецепт ( разработчики Коре-дуля ).
*
Насчет хитрости с экономией ПЗУ - не я разработчик, я просто привел пример - не стоит упускать из внимания, что готово было в 1988 г. - т.е. начали свистать с оригинала году так в 1983. К тому же я привел законченный вариант - 200 нс РФка - её не обойти ( напрямую ).
Были, конечно, и масочные ТТЛШ ПЗУ - с временами менее 60 нс,
но мне такие конструктивы не извесны ( т.е. готовые умножители 12 бит ).
*
Вот клянчил у Ю.Л. Отрохова ТО на его камень 1013ВМ1 - хрен дал
( официально ). И даже не счел нужным ( он ) упомянуть, что полно камушков без "К" - по этому и не дает ТО ( официально ) :
http://forum.ixbt.com/topic.cgi?id=64:3394-153 ( Иванов И.И. = MM )
