nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Moderator: Shaos
-
aahzma

- Junior
- Posts: 5
- Joined: 26 Jul 2021 01:11
Re: nedoPC-580 (SMP на 5 процессорах 8080)
Забавно... Я именно в 2021 году задумался о создании ПК "а-ля 80е", по мотивам всех тогдашних 580-х изделий... и понял, что надо отталкиваться от многопроцессорной масштабируемой архитектуры. Но, на удивление, кроме размышлений ничего не нашел. Тема умерла, как я понимаю?
Никогда не поздно что-то изменить. Поздно лишь сожалеть...
-
VGrad
- Maniac
- Posts: 208
- Joined: 18 Nov 2013 15:15
- Location: все оттуда ;)
Re: nedoPC-580 (SMP на 5 процессорах 8080)
Зачем ? Этим актуально было заниматься в середине 80-х !aahzma wrote:Забавно... Я именно в 2021 году задумался о создании ПК "а-ля 80е", по мотивам всех тогдашних 580-х изделий...
Читай как сделана шина MultiBUS (русское название "И-41").aahzma wrote: и понял, что надо отталкиваться от многопроцессорной масштабируемой архитектуры. Но, на удивление, кроме размышлений ничего не нашел. Тема умерла, как я понимаю?
Потом неплохо бы ОС которая это поддерживает.
Если нет зацикленности на 580 процессоре, то сразу перейти к 1810, компьютеру "Нейрон И9.66".
-
Lavr

- Supreme God
- Posts: 16680
- Joined: 21 Oct 2009 08:08
- Location: Россия
Re: nedoPC-580 (SMP на 5 процессорах 8080)
Нет, не умерла... иногда она неожиданно оживает...aahzma wrote: Тема умерла, как я понимаю?
Всё зависит от того, что хочется получить в итоге.
iLavr
-
Shaos

- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re:
В продолжение идей со страницы 23 (август 2012):
viewtopic.php?f=46&t=7540&start=330
Либо вообще разнести семафоры по разным номерам портов и писать туда приоритет с которым проц хочет ресурсом попользоваться - арбитр будет сравнивать приоритеты и выстраивать запросы в очередь в правильном порядке, хотя наверное это уже черезчур сложно (а если делать руками супервизора, которым будет выступать 5й процессор, то ещё и медленно)
P.S. Эти "аппаратные" семафоры можно рассматривать как самые настоящие сигнальные семафоры - с помощью них рабочие процы отправляют сигнал процу-арбитру и ждут пока этот сигнал не будет принят. Если добавлять приоритеты 0...7 к семафорам, то каждый проц должен будет запоминать не только номер семафора, но и номер приоритета на регистре, а проц-арбитр должен будет эти регистры всех процов обходить и смотреть если от кого-то пришёл какой-то запрос. Плюс к этому можно сделать передачу символов между процессорами - эдакие каналы от любого процессора к любому процессору. Например запись в порт 0 будет означать передачу символа в 0й процессор (скажем для вывода в терминал). Запись в порт 1 - передача символа в 1й процессор и т.д. Чтение из портов будет означать принятие символа из соответствующего процессора (но не для порта 0, чтение из которого будет возвращать кол-во процессоров в системе и номер процессора). Запись в порт будет подвешивать процессор-передатчик, пока на той стороне не прочитают посланный байт. Если процессор попытается послать символ сам себе (например процессор 3 выполнит команду OUT 3), то он самозаблокируется до перезагрузки системы. Плюс к этому процессор 0 (арбитр/супервизор) может иметь специальную логику, предотвращающую отпускание процессора-передатчика в момент чтения соответствующего порта нулевым процессором т.к. он должен отпускать процессоры в специальном порядке в соответствии с приоритетами (это можно сделать путём записи в порт 0 нужного битика) - для него также чтение из порта 0 будет иметь иной смысл - он будет возвращать битовый набор, где каждый бит сигнализирует, что тот или иной процессор послал байт в канал и ждёт его анализа.
viewtopic.php?f=46&t=7540&start=330
Подумалось тут мне, что чего попусту крутиться в цикле? Можно при попытке записи в порт 7 останавливать проц через сброс READY, если аппаратный арбитр решит не давать ему доступ к ресурсу:Shaos wrote:угуHardWareMan wrote:Латчить по SYNC AND F1 в одну ТМ2. Все верно.Shaos wrote:P.S. Я смотрю что слово статуса хватать с шины данных совсем не сложно - так что наверное будут у нас нормальные порты с командами IN и OUT
По большому счёту нам только 2 бита нужны из этого слова состояния - INP и OUT
тогда обращение к хардверному семафору, защищающему доступ к софтверным мьютексам (а также 7 другим критическим абстракциям - по 1 биту на каждую), будет выглядеть так:
P.S. Биты в порту 7 можно поделить между следующими "семафорами":Code: Select all
DI MVI A,#10 OUT 7 ; пусть на этом порту находятся 8 хардверных семафоров LOOP: IN 7 ANI #10 ; бит 4 пусть будет семафором мьютексов JZ LOOP ; крутимся пока ноль (значит наш запрос семафора ещё не дошёл) ; далее висим на холде либо идём дальше ... XRA A OUT 7 EIP.P.S. Семафоры внутренние, т.е. не входят в публично доступный API - это лишь соглашение о взаимодействии супервайзера (процессор номер ноль) и операционки на рабочих процессорах...Code: Select all
bit 0 - SEM_PRO (доступ к списку всех процессов) bit 1 - SEM_ACT (доступ к списку активных процессов) bit 2 - SEM_SCR (доступ к буферу вывода на экран) bit 3 - SEM_IOB (доступ к буферу обмена с внешними устройствами) bit 4 - SEM_MUX (доступ к списку программных мьютексов) bit 5 - SEM_PIP (доступ к FIFO каналам обмена данными) bit 6 - SEM_MSG (доступ к очередям сообщений) bit 7 - SEM_AUX (дополнительный семафор)
Либо вообще разнести семафоры по разным номерам портов и писать туда приоритет с которым проц хочет ресурсом попользоваться - арбитр будет сравнивать приоритеты и выстраивать запросы в очередь в правильном порядке, хотя наверное это уже черезчур сложно (а если делать руками супервизора, которым будет выступать 5й процессор, то ещё и медленно)
P.S. Эти "аппаратные" семафоры можно рассматривать как самые настоящие сигнальные семафоры - с помощью них рабочие процы отправляют сигнал процу-арбитру и ждут пока этот сигнал не будет принят. Если добавлять приоритеты 0...7 к семафорам, то каждый проц должен будет запоминать не только номер семафора, но и номер приоритета на регистре, а проц-арбитр должен будет эти регистры всех процов обходить и смотреть если от кого-то пришёл какой-то запрос. Плюс к этому можно сделать передачу символов между процессорами - эдакие каналы от любого процессора к любому процессору. Например запись в порт 0 будет означать передачу символа в 0й процессор (скажем для вывода в терминал). Запись в порт 1 - передача символа в 1й процессор и т.д. Чтение из портов будет означать принятие символа из соответствующего процессора (но не для порта 0, чтение из которого будет возвращать кол-во процессоров в системе и номер процессора). Запись в порт будет подвешивать процессор-передатчик, пока на той стороне не прочитают посланный байт. Если процессор попытается послать символ сам себе (например процессор 3 выполнит команду OUT 3), то он самозаблокируется до перезагрузки системы. Плюс к этому процессор 0 (арбитр/супервизор) может иметь специальную логику, предотвращающую отпускание процессора-передатчика в момент чтения соответствующего порта нулевым процессором т.к. он должен отпускать процессоры в специальном порядке в соответствии с приоритетами (это можно сделать путём записи в порт 0 нужного битика) - для него также чтение из порта 0 будет иметь иной смысл - он будет возвращать битовый набор, где каждый бит сигнализирует, что тот или иной процессор послал байт в канал и ждёт его анализа.
You do not have the required permissions to view the files attached to this post.
Я тут за главного - если что шлите мыло на me собака shaos точка net
-
Shaos
- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Чего-то подумалось, что для реализации этих параллельных каналов связи между процессорами можно взять ВВ55е  |
|
Даже можно попробовать задействовать хендшейк, который включается в одном из режимов их работы!
Даже можно попробовать задействовать хендшейк, который включается в одном из режимов их работы!
Я тут за главного - если что шлите мыло на me собака shaos точка net
-
BarsMonster

- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Поразмыслил над темой 10 лет...
Предыдущая идея с 580 с обвязкой на сдвиговых регистрах управляемых CPLD - мне по-прежнему нравится. Но не канонично, хоть на центральной CPLD сколько хочешь их можно объеденить (8-16 и более), особенно если где-то влезет небольшой кеш.
О более каноничных вариантах:
1) На 2 фазы шину разбить по-Орионовски - это уже классика. Может и 4 штуки получится - но тяжело, если декодер памяти тяжелый. Это уже обсуждено детально.
2) 2 процессора друг друга придерживают за HOLD по очереди - насколько такое реально провернуть? 580-й же шину теребонькает хорошо если 50% времени, вот и разделят свою фазу. КПД пусть не 100% будет, а 75 - уже успех.
3) Dual-port SRAM. Позволит с обоих сторон подвесить по 4шт по схемам #1+#2. Но тут все упрется в размер памяти и неканоничность.
Что думаете про #2 - это же как раз классический подход для SMP? Конечно он гораздо лучше работает когда есть L1-кеш, но из-за того что сам по себе 580-й медленно работает, может и сработать....
Предыдущая идея с 580 с обвязкой на сдвиговых регистрах управляемых CPLD - мне по-прежнему нравится. Но не канонично, хоть на центральной CPLD сколько хочешь их можно объеденить (8-16 и более), особенно если где-то влезет небольшой кеш.
О более каноничных вариантах:
1) На 2 фазы шину разбить по-Орионовски - это уже классика. Может и 4 штуки получится - но тяжело, если декодер памяти тяжелый. Это уже обсуждено детально.
2) 2 процессора друг друга придерживают за HOLD по очереди - насколько такое реально провернуть? 580-й же шину теребонькает хорошо если 50% времени, вот и разделят свою фазу. КПД пусть не 100% будет, а 75 - уже успех.
3) Dual-port SRAM. Позволит с обоих сторон подвесить по 4шт по схемам #1+#2. Но тут все упрется в размер памяти и неканоничность.
Что думаете про #2 - это же как раз классический подход для SMP? Конечно он гораздо лучше работает когда есть L1-кеш, но из-за того что сам по себе 580-й медленно работает, может и сработать....
Last edited by BarsMonster on 31 Jul 2022 19:07, edited 4 times in total.
-
BarsMonster
- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Второй вопрос про разделение адресного пространства.
Разделение стека мне очень нравится, жаль что код и данные не поделить без диких извращений.
Правильно ли я понимаю, что стек через слово состояния отделить можно только в 580/8080 и 8085, но не Z80?
Разделение стека мне очень нравится, жаль что код и данные не поделить без диких извращений.
Правильно ли я понимаю, что стек через слово состояния отделить можно только в 580/8080 и 8085, но не Z80?
-
Shaos
- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Ну решение иметь 4 проца, которые в параллель дёргают быструю оперативную память, причём абсолютно прозрачно и не наступая друг другу на пятки, как мне кажется выглядит самым красивым 
Я тут за главного - если что шлите мыло на me собака shaos точка net
-
BarsMonster
- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Наиболее красивым, но и наиболее оторванным от современных концепций SMP. Т.к. работать будет только потому что память и драйверы по технологии 90-350нм, а не 6мкм. Ну и масштабирование упирается в потолок.Shaos wrote:Ну решение иметь 4 проца, которые в параллель дёргают быструю оперативную память, причём абсолютно прозрачно и не наступая друг другу на пятки, как мне кажется выглядит самым красивым
Современный SMP - всегда с тормозной шиной. И как выяснили раньше SMP плохо работает без кеша.
Потому возникла такая идея: у каждого процессора своя пара страниц памяти (128кб), т.е. страницы 0 и 1. Там может быть стек (по желанию), локальный код, локальные данные.
А когда проц лезет на страницы 2 и выше, на устройства - вот там все идет через диспетчер шины, медленно. А то и вовсе без диспетчера, а просто по очереди все получают слоты общей шины (т.е. медленно).
В этом случае мы получаем что-то похожее на современные архитектуры, и условно неограниченное масштабирование. Конечно, если написать код который будет случайно дергать глобальную память одновременно со всех ядер - будет тормозить, как и в современных компьютерах. Т.е. по факту будет L1 кеш с "ручным" управлением. В лучшем случае загрузку/выгрузку "кеша" можно положить на КПДП во второй таймслот локальной шины по-Орионовски, но это уже чтобы мастерство показать.
-
Shaos
- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Там же снаружи шина тормозная, а внутри - шустрая, не?BarsMonster wrote:Современный SMP - всегда с тормозной шиной. И как выяснили раньше SMP плохо работает без кеша.
А зачем медленно, если можно сделать прозрачно и быстро?BarsMonster wrote:А когда проц лезет на страницы 2 и выше, на устройства - вот там все идет через диспетчер шины, медленно. А то и вовсе без диспетчера, а просто по очереди все получают слоты общей шины (т.е. медленно).
До 4 ядер вместе - быстро, а уже эти четвёрки можно сажать на общую "медленную" шину и расширять в "условно неограниченное масштабирование"...
Я тут за главного - если что шлите мыло на me собака shaos точка net
-
BarsMonster
- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Ну это тогда будет уже сложная многоуровневая система, которую без миллиарда не осилитьShaos wrote:До 4 ядер вместе - быстро, а уже эти четвёрки можно сажать на общую "медленную" шину и расширять в "условно неограниченное масштабирование"...
NUMA и все такое...
Т.е. то что я предлагаю - это условный подход x86 2000-х.
А то что ты - это подход x86 из 2020-х
-
Shaos
- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Ну мы же современные люди 
А к этой четвёрке можно и кеш присобачить, через который будет производиться доступ к внешней "медленной" памяти
А к этой четвёрке можно и кеш присобачить, через который будет производиться доступ к внешней "медленной" памяти
Я тут за главного - если что шлите мыло на me собака shaos точка net
-
oldlazycat

- Fanat
- Posts: 59
- Joined: 18 Nov 2022 06:33
- Location: Урюпинск
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Дочитал 27 страниц!
И каков итог? Получилось впихнуть невпихуемое?
А, ведь, есть прекрасный Z280, заточенный под мультипроцессорность! Может, его попробуем? viewtopic.php?f=89&t=8954
И каков итог? Получилось впихнуть невпихуемое?
А, ведь, есть прекрасный Z280, заточенный под мультипроцессорность! Может, его попробуем? viewtopic.php?f=89&t=8954
Two Beer? Or not Two Beer?
-
Lavr
- Supreme God
- Posts: 16680
- Joined: 21 Oct 2009 08:08
- Location: Россия
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Ну почему же "невпихуемое"? Вполне даже впихуемое!oldlazycat wrote:Дочитал 27 страниц!
И каков итог? Получилось впихнуть невпихуемое?
Два микропроцессора вполне впихнули:
Двухпроцессорная система на микропроцессорах Intel 8080.
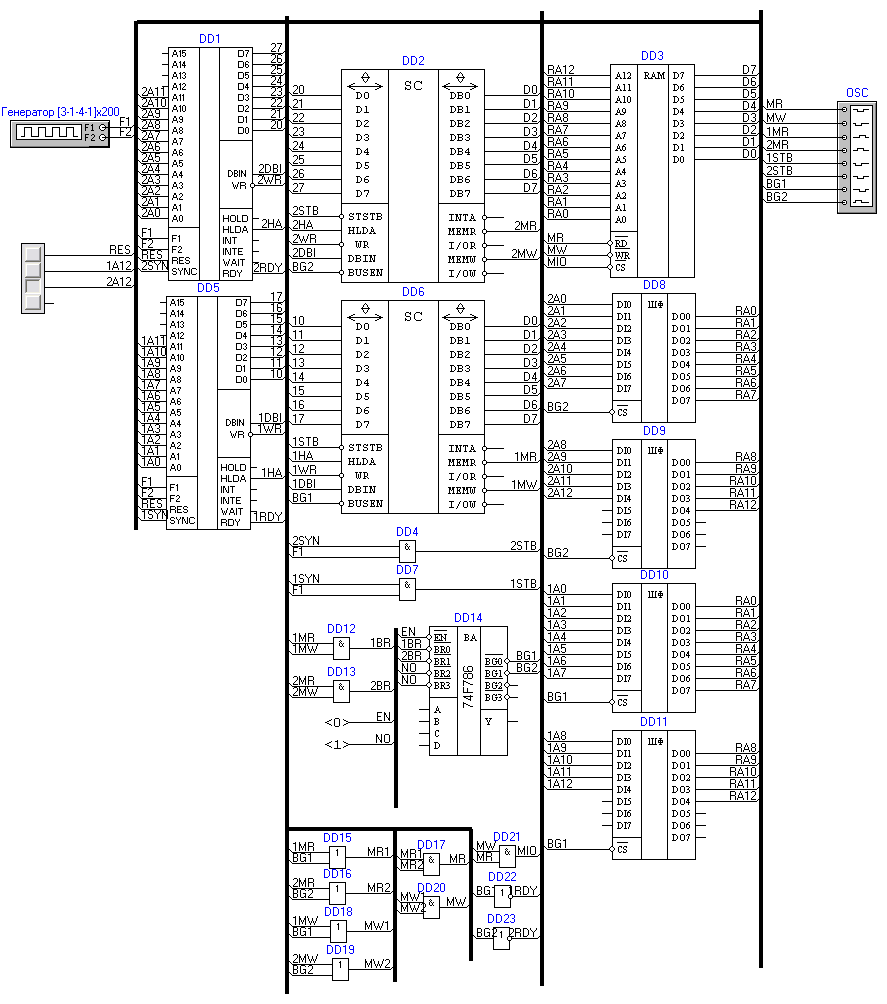
Просто, насколько я понимаю, у всех участников были разные ожидания от этого проекта...
Меня лично результат даже с двумя микропроцессорами разочаровал.
iLavr
-
Shaos
- Admin
- Posts: 24014
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Re: nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Да и 4 проца тоже норм должно работать (если железохрен не обделался с выкладками)
Я тут за главного - если что шлите мыло на me собака shaos точка net
