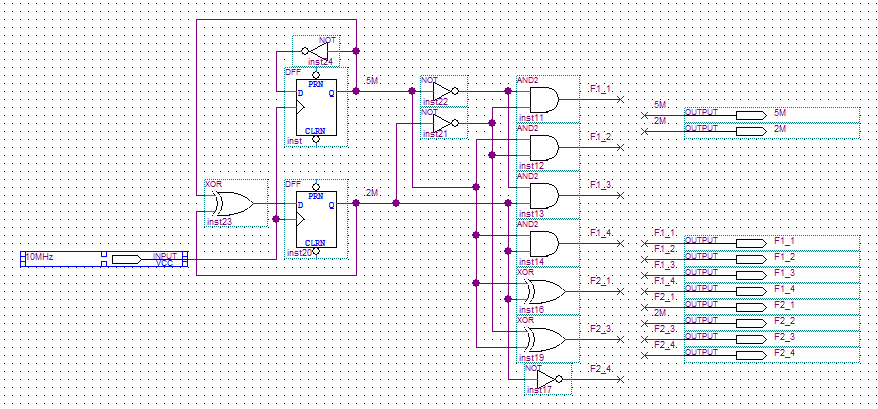
Shaos wrote:Shaos wrote:Я тут подумал, что чисто программно мьютексы не сделать - всё равно будет вероятность того, что к ячейке с состоянием мьютекса процессы обратятся одновременно и одновременно же попробуют его залочить. Поэтому в системе должен быть как минимум один аппаратный мьютекс, который будет закрывать доступ к программным мьютексам, причём закрывать серъёзно - т.е. останавливая все процессоры кроме одного (даже если обращается больше одного должен быть выбран один). Например путём вывода в некий порт программа будет говорить железяке, что она хочет поработать с одним из мьютексов (захватить или освободить), в этот момент железяка остановит все процессоры кроме просящего (либо первого из просящих), далее программа устанавливает (и идёт дальше либо запоминает что она должна локнуться) либо сбрасывает мьютекс и пишет в другой порт чтобы сигнализировать о том, что работа с мьютексами закончена - далее железяка отпускает все процессы, а просящий процесс либо висит на программном локе (ожидая когда программный мьютекс отпустят при этом ос может отдавать управление другим тредам на этом же процессоре), либо идёт дальше - в зависимости от результата лочки-анлочки программного мьютекса. Вобщем как-то так...
Вобщем информация обо всех глобальных мьютексах будет храниться в общей непереключаемой памяти (#C800...#CFFF). Любой процесс может в любой момент прочитать состояние любого мьютекса, однако чтобы локнуть или анлокнуть мьютекс, надо будет уведомить супервизора, что процесс хочет зайти в критическую секцию - для этого можно обратиться к какому-то специальному адресу (упрощаем железо - портов нету), предварительно запретив прерывания:
DI
MVI A,1
STA #FFFF
Это вызывает прерывание процессора-супервайзера. Далее процесс ожидает подтверждения - читает оттуда байт и ждёт когда младший бит станет равен нулю:
LOOP:
LDA #FFFF
RAR
JC LOOP
В момент подтверждения ожидающий процессор либо останавливается супервизором (если эта критическая секция уже локнута другим процессором либо процессор с более низким номером также хочет обратиться к критической секции), либо идёт дальше - локать или анлокать программный мьютекс.
Если интересующий нас мьютекс свободен (бит мьютекса сброшен) и процесс хочет его локнуть, то бит мьютекса взводится, а супервайзер уведомляется, что критическая секция покидается:
XRA A
STA #FFFF
EI
После этого супервайзер отпускает все остановленные процессоры, если таковые были.
Если интересующий нас мьютекс свободен, но процесс хочет его анлокнуть, то это ошибка, теоретически приводящая к трапу.
Если интересующий нас мьютекс локнут (бит мьютекса взведён) и процесс хочет его локнуть, то нужно ожидать анлока - для этого мы уведомляем супервизора что покидаем критическую секцию:
XRA A
STA #FFFF
EI
и висим в цикле ожидая сброса бита мьютекса, чтобы попытаться его локнуть когда он освободится (опять же зайдя в критическую секцию). При этом текущий процессор может переключить контекст, отдав вычислительные ресурсы другому процессу, ожидающему своего кванта времени.
Если интересующий нас мьютекс локнут и процесс хочет его отпустить (надо ли проверять то, что мьютекс отпускается именно тем процессом, который его локал?), то бит мьютекса сбрасывается и супервизор уведомляется о том, что критическая секция покинута:
XRA A
STA #FFFF
EI