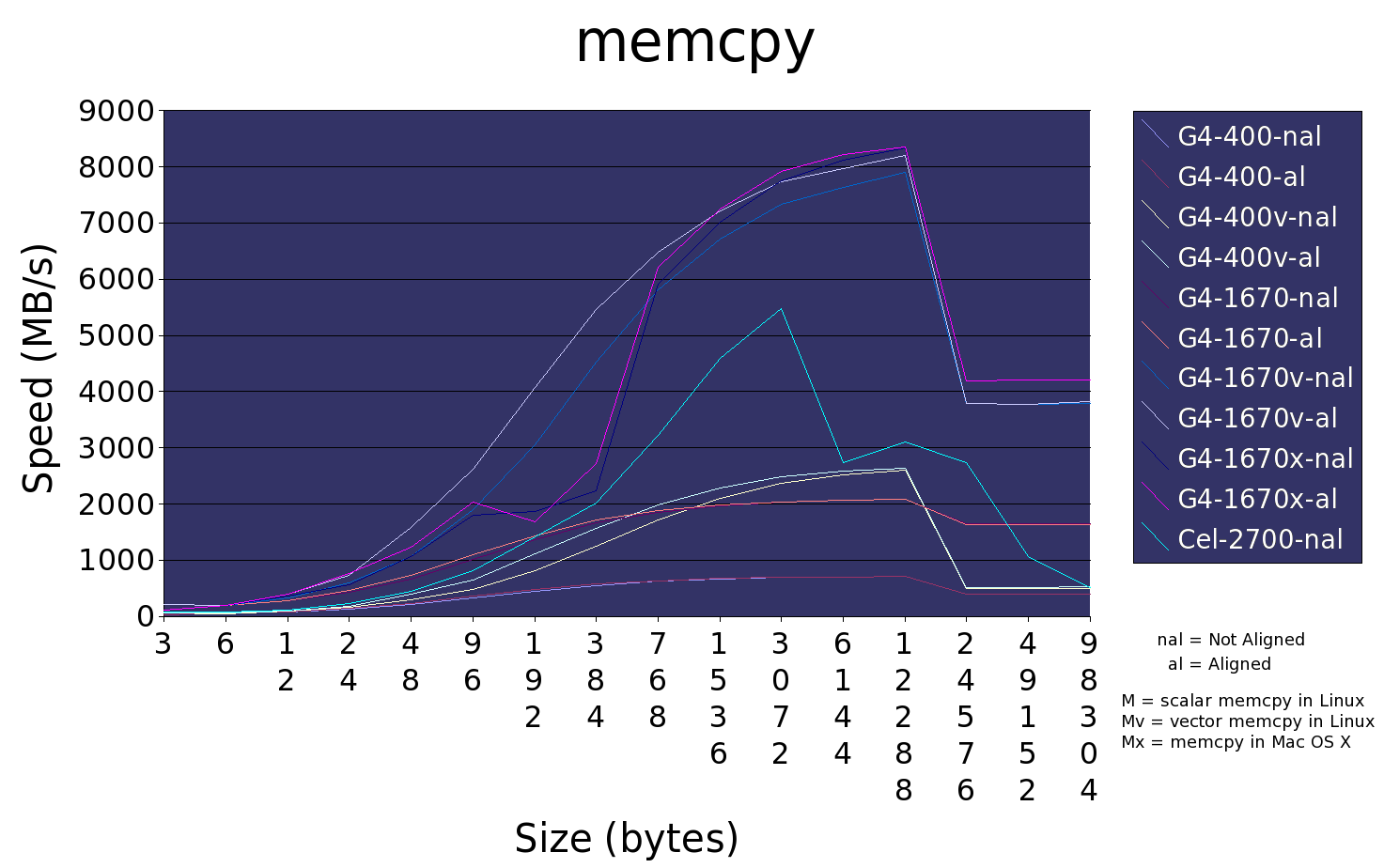
Сравнение быстродействия целерона 2.7 ГГц c поверпц G4 400 МГц и 1.67 ГГц через memcpy:
Как видно векторизированный memcpy на PowerPC 1.67 ГГц почти в 2 раза быстрее целерона 2.7 ГГц, который в некоторых случаях даже сравним по скорости с векторизированным memcpy на PowerPC 400 МГц. Также оказалось что memcpy векторизирован по умолчанию в Mac OS X (тестовая прога собиралась без каких бы то ни было оптимизирующих ключей). Вот текст тестовой программы:
Code: Select all
/* Alexander Shabarshin - 26 Apr 2008 */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define POOLSIZE 8*1024*1024
#define POOLSTEP 128*1024
#define A16MASK 0xFFFFFFF0
#define NTRIES 10
#define MTRIES 1000000
unsigned char* gpool;
int rt[NTRIES];
int pt[NTRIES];
int tt[NTRIES];
int main()
{
FILE *f;
double d1,d2;
clock_t t1,t2;
unsigned char *pool,*p1,*p2;
int i,j,k,r,s,b1,b2,e1,e2;
printf("TEST G4\n");
if(RAND_MAX < POOLSIZE)
{
printf("too short random generator - RAND_MAX=%i\n",RAND_MAX);
return -1;
}
gpool = (unsigned char*)malloc(POOLSIZE+512);
if(gpool==NULL) return -2;
pool = gpool;
while((int)pool&511) pool++;
printf("pool = 0x%8.8X\n",(int)pool);
srand(time(NULL));
for(i=0;i<POOLSIZE;i++)
{
do { r = rand()&255; } while(!r);
pool[i] = r;
}
printf("randomized %i bytes\n",POOLSIZE);
f = fopen("memcpy.csv","wt");
if(f==NULL)
{
free(gpool);
return -3;
}
fprintf(f,"size,nal,al\n");
for(i=0;i<NTRIES;i++)
{
rt[i] = rand()%(POOLSIZE-(POOLSTEP<<1));
pt[i] = POOLSTEP + (rand()%POOLSTEP);
}
for(j=3;j<100000;j<<=1)
{
printf("size %i\n",j);
s = 0;
for(k=0;k<NTRIES;k++)
{
p1 = &pool[rt[k]];
p2 = &p1[pt[k]];
t1 = clock();
for(i=0;i<MTRIES;i+=10)
{
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
}
t2 = clock();
tt[k] = (int)((t2-t1)/(CLOCKS_PER_SEC/1000.0));
// printf("t[%i]=%i ms\n",k,tt[k]);
s += tt[k];
}
s /= NTRIES;
d1 = MTRIES/1.024*j/1024.0/s;
printf("nal : %i ms -> %4.2f MB/s\n",s,d1);
s = 0;
for(k=0;k<NTRIES;k++)
{
p1 = &pool[rt[k]&A16MASK];
p2 = &p1[pt[k]&A16MASK];
t1 = clock();
for(i=0;i<MTRIES;i+=10)
{
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
memcpy(p1,p2,j);
}
t2 = clock();
tt[k] = (int)((t2-t1)/(CLOCKS_PER_SEC/1000.0));
// printf("t[%i]=%i ms\n",k,tt[k]);
s += tt[k];
}
s /= NTRIES;
d2 = MTRIES/1.024*j/1024.0/s;
printf(" al : %i ms -> %4.2lf MB/s\n",s,d2);
fprintf(f,"%i,%4.2f,%4.2f\n",j,d1,d2);
}
fclose(f);
free(gpool);
return 0;
}
Для проверки векторизированного варианта memcpy заменялся на vec_memcpy из состава