library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use IEEE.numeric_std.ALL;
entity Clock_Divider is
port ( clk,reset: in std_logic;
clock_out: out std_logic);
end Clock_Divider;
architecture bhv of Clock_Divider is
signal count: integer:=1;
signal tmp : std_logic := '0';
begin
process(clk,reset)
begin
if(reset='1') then
count<=1;
tmp<='0';
elsif(clk'event and clk='1') then
count <=count+1;
if (count = 1000000) then
tmp <= NOT tmp;
count <= 1;
end if;
end if;
clock_out <= tmp;
end process;
end bhv;
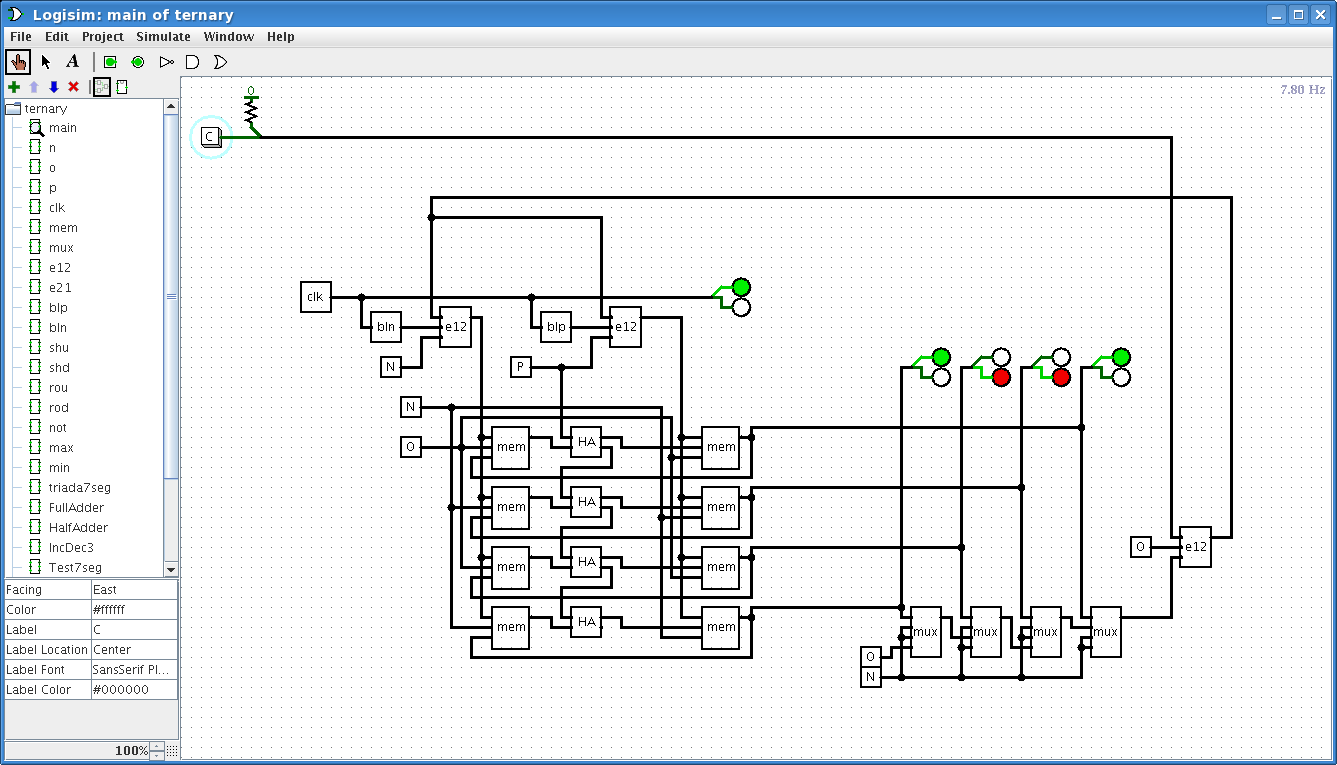
Теперь вот задействовал тактовый сигнал 1.8432 МГц, что на плате, и делю его на миллион (см.выше), чтобы глазами видеть NOPONOPONOPO после ternary_clk
Пора заталкивать в CPLD троичный счётчик
P.S. bln (block negative) это e21(s,O,P) или mux(s,O,O,P),
а blp (block positive) это e12(s,N,O) или mux(s,N,O,O).
Я тут за главного - если что шлите мыло на me собака shaos точка net
Троичный счётчик вроде считает - интересный момент, что каждый новый троичный разряд счётчика добавляет только 2 макроячейки, что несколько неожиданно, т.к. я рассчитвал на 4 потому что в каждом разряде у нас по 2 блока MEM
library IEEE;
use IEEE.STD_LOGIC_1164.ALL;
use ternary.all;
entity main is
Port ( clk : in bit;
res : in bit;
a : in FakeTrit;
b : in FakeTrit;
c : in FakeTrit;
s1 : out FakeTrit;
s2 : out FakeTrit;
s3 : out FakeTrit;
led : out bit);
end main;
architecture Behavioral of main is
signal a1,b1,c1,ss0,ss1,ss2,ss3,ss4 : FakeTrit;
signal pclk,pclk1,nclk,nclk1,res0,res1,m1,m2,m3,m4,h1,h2,h3,h4,g1,g2,g3 : FakeTrit;
signal tmp_clk_std, tmp_iclk_std : STD_LOGIC;
signal tmp_clk : BIT;
COMPONENT Clock_Divider
PORT(
clk : IN std_logic;
reset : IN std_logic;
clock_out : OUT std_logic
);
END COMPONENT;
COMPONENT Half_Adder
Port ( a : in FakeTrit;
b : in FakeTrit;
s : out FakeTrit;
c : out FakeTrit
);
END COMPONENT;
FUNCTION io_invert(T: FakeTrit) RETURN FakeTrit IS
begin
case T is
when N =>
return P;
when O =>
return X;
when P =>
return N;
when others =>
return O;
end case;
end;
begin
a1 <= io_invert(a);
b1 <= io_invert(b);
c1 <= io_invert(c);
tmp_iclk_std <= to_stdulogic(clk);
div1: Clock_Divider port map( clk => tmp_iclk_std, reset => '0', clock_out => tmp_clk_std );
tmp_clk <= to_bit(tmp_clk_std);
res0(0) <= '0';
res0(1) <= res;
res1 <= res0;
clk1: ternary_clock port map( B_C => tmp_clk, T_C => ss0 );
mux1: ternary_mux port map( T_S => ss0, T_N => O, T_O => O, T_P => P, T_C => pclk );
mux2: ternary_mux port map( T_S => res1, T_N => pclk, T_O => N, T_P => N, T_C => pclk1 );
mux3: ternary_mux port map( T_S => ss0, T_N => N, T_O => O, T_P => O, T_C => nclk );
mux4: ternary_mux port map( T_S => res1, T_N => nclk, T_O => P, T_P => P, T_C => nclk1 );
mem1: ternary_mem port map( T_S => pclk1, T_N => O, T_P => ss1, T_Q => m1 );
ha1: Half_Adder port map( a => P, b => m1, s => h1, c => g1 );
mem2: ternary_mem port map( T_S => nclk1, T_N => h1, T_P => O, T_Q => ss1 );
mem3: ternary_mem port map( T_S => pclk1, T_N => O, T_P => ss2, T_Q => m2 );
ha2: Half_Adder port map( a => g1, b => m2, s => h2, c => g2 );
mem4: ternary_mem port map( T_S => nclk1, T_N => h2, T_P => O, T_Q => ss2 );
mem5: ternary_mem port map( T_S => pclk1, T_N => O, T_P => ss3, T_Q => m3 );
ha3: Half_Adder port map( a => g2, b => m3, s => h3, c => g3 );
mem6: ternary_mem port map( T_S => nclk1, T_N => h3, T_P => O, T_Q => ss3 );
s1 <= io_invert(ss1);
s2 <= io_invert(ss2);
s3 <= io_invert(ss3);
led <= to_bit(tmp_clk_std);
end Behavioral;
use ternary.all;
entity Half_Adder is
Port ( a : in FakeTrit;
b : in FakeTrit;
s : out FakeTrit;
c : out FakeTrit
);
end Half_Adder;
architecture Behavioral of Half_Adder is
signal r1,r2,r3,r4,r5,r6 : FakeTrit;
begin
process (a,b)
begin
r1 <= mux(a,P,N,O);
r2 <= mux(a,O,P,N);
r3 <= mux(b,r1,a,r2);
r4 <= e12(a,N,O);
r5 <= e21(a,O,P);
r6 <= mux(b,r4,O,r5);
s <= r3;
c <= r6;
end process;
end Behavioral;
NET "clk" LOC = "P38" | IOSTANDARD = LVTTL ;
NET "res" LOC = "P143" | IOSTANDARD = LVTTL ;
NET "a<0>" LOC = "P140" | IOSTANDARD = LVTTL ;
NET "a<1>" LOC = "P142" | IOSTANDARD = LVTTL ;
NET "b<0>" LOC = "P138" | IOSTANDARD = LVTTL ;
NET "b<1>" LOC = "P139" | IOSTANDARD = LVTTL ;
NET "c<0>" LOC = "P136" | IOSTANDARD = LVTTL ;
NET "c<1>" LOC = "P137" | IOSTANDARD = LVTTL ;
NET "s3<0>" LOC = "P82" | IOSTANDARD = LVTTL ;
NET "s3<1>" LOC = "P83" | IOSTANDARD = LVTTL ;
NET "s2<0>" LOC = "P85" | IOSTANDARD = LVTTL ;
NET "s2<1>" LOC = "P86" | IOSTANDARD = LVTTL ;
NET "s1<0>" LOC = "P87" | IOSTANDARD = LVTTL ;
NET "s1<1>" LOC = "P88" | IOSTANDARD = LVTTL ;
NET "led" LOC = "P92" | IOSTANDARD = LVTTL ;
Плюс ещё использовался модуль делителя частоты, что я приводил чуть выше, но в данном случае я делю на 460800, чтобы счётчик считал секунды (тактовая частота при преобразовании в троичную синхру делится на 4).
P.S. На этом этапе VHDL код постепенно начинает превращаться в месиво - думаю пора браться за автоматизацию...
На видео запечетлено, как оно после сброса кнопкой (вход res) считает от OOO (0) до PPP (+13) и далее NNN (-13) и вверх до OOO (0) с периодом в 1 секунду (частоту двоичного такта, которая выше в 4 раза, можно пронаблюдать на бортовом красном светодиодике)
Я тут за главного - если что шлите мыло на me собака shaos точка net
Shaos wrote:Троичный счётчик вроде считает - интересный момент, что каждый новый троичный разряд счётчика добавляет только 2 макроячейки, что несколько неожиданно, т.к. я рассчитвал на 4 потому что в каждом разряде у нас по 2 блока MEM
В этот CoolRunner-II с 256 макроячейками можно выходит затолкать 128-тритный счётчик
Я тут за главного - если что шлите мыло на me собака shaos точка net
Надо чтоли про средства отладки подумать - чтобы можно было сигнал в любой (или почти любой) точке изнутри выдать наружу и померять - либо путём адресации к конкретным точкам в паузе, либо путём потритового сдвига наружу (опять же в паузе) аналогично https://en.wikipedia.org/wiki/JTAG или примерно как тут: Троичный вариант SPI
Первый вариант потребует больше ног (т.к. адрес задаётся параллельно), а для второго можно обойтись одним троичным входом и одним троичным выходом:
Input TMC - ternary mode/clock
Output TDO - ternary data out
Типа подаём на TMC последовательность ONOPOPOPOPOP... по N оно считает значения во внутренний многотритовый регистр, а по P будет эти значения сдвигать в TDO, где мы будем программно их считывать и отображать в отладчике
P.S. Либо если у нас всё теже MEM-защёлки по уровню, то тактировать их также NOPONOPONOPO имея по 2 MEM на тестовый трит, но тогда придётся иметь отдельный вход на команду записи состояние схемы в защёлки (и тот же трит можно использовать для записи из защёлок в схему для изменения состояния в будущем - тогда ещё их вход TDI добавится)
P.P.S. Чтобы не путаться с JTAG-ом можно назвать сигналы иначе:
TTC - ternary clock (NOPONOPONOPO)
TTS - ternary control (P to read and N to write)
TTO - ternary test output
TTI - ternary test input (optional)
Тогда отладка будет выглядеть так:
- останавливаем глобальный клок (схема в паузе)
- подаём на TTS уровень P и возвращаем обратно (в этом случае все тестовые защёлки запомнят состояние точек)
- подаём на TTC последовательность NOPONOPONOPO одновременно снимая значения с выхода TTO после каждого P
P.P.P.S. На самом деле внутренние тестовые защёлки могут защелкивать текущее состояние постянно сами по глобальному клоку (скажем на P) - в этом случае вход TTS ненужен и в простейшем случае нам надо будет только TTC и TTO
Я тут за главного - если что шлите мыло на me собака shaos точка net
Shaos wrote:На этом этапе VHDL код постепенно начинает превращаться в месиво - думаю пора браться за автоматизацию...
Можно попробовать продолжать в том же духе, вручную переписывая логисимовскую схему на VHDL - для этого правда придётся вооружиться распечаткой модели, где каждому соединению приписано имя...
Shaos wrote:Надо чтоли про средства отладки подумать - чтобы можно было сигнал в любой (или почти любой) точке изнутри выдать наружу и померять - либо путём адресации к конкретным точкам в паузе, либо путём потритового сдвига наружу (опять же в паузе) аналогично https://en.wikipedia.org/wiki/JTAG или примерно как тут: Троичный вариант SPI
Первый вариант потребует больше ног (т.к. адрес задаётся параллельно), а для второго можно обойтись одним троичным входом и одним троичным выходом
А пока можно просто необходимые точки через VHDL цеплять к свободным ногам микросхемы, которых дофига (118)
Я тут за главного - если что шлите мыло на me собака shaos точка net
Есть такой HDL, называется Lola-2. По синтаксису похож на Паскаль (точнее - Оберон). Транслируется в Verilog и дальше обрабатывается стандартно для этого языка. Я вот думаю, для создания троичных схем в FPGA стоило-бы сделать некую Lola-3, которая транслировалась-бы в Verilog, а лучше - в SystemVerilog.
kvas wrote:Есть такой HDL, называется Lola-2. По синтаксису похож на Паскаль (точнее - Оберон). Транслируется в Verilog и дальше обрабатывается стандартно для этого языка. Я вот думаю, для создания троичных схем в FPGA стоило-бы сделать некую Lola-3, которая транслировалась-бы в Verilog, а лучше - в SystemVerilog.
kvas wrote:Есть такой HDL, называется Lola-2. По синтаксису похож на Паскаль (точнее - Оберон). Транслируется в Verilog и дальше обрабатывается стандартно для этого языка. Я вот думаю, для создания троичных схем в FPGA стоило-бы сделать некую Lola-3, которая транслировалась-бы в Verilog, а лучше - в SystemVerilog.
Ну, "прошлый век" это не аргумент. Например, системе размножения млекопитающих уже не одна сотня миллионов лет, но думаю, что большинство читателей форума появилось на свет именно благодаря ей
К тому-же по предложенной ссылке, как я понял, не HDL-синтезатор, а HDL-симулятор, это несколько разные классы ПО. Для моделирования работы предлагаемый там код вполне успешно применим. А вот для синтеза заливаемой в FPGA прошивки уже нужно нечто другое. Проект "Оберон-2013" как раз прекрасный пример того, как с нуля разработать и воплотить на FPGA вычислительную систему нового типа. Это практически то-же самое, что и планируется в этой теме форума. Хотя ЦП я-бы "срисовывал" скорее не с Виртовского, а с J1a (вот тут о его предшественнике J1 http://excamera.com/sphinx/fpga-j1.html есть кое-что).
Shaos wrote:Я почти вплотную приблизился к созданию троичного компьютера вот на этом железе:
Конечно же это будет 3niti alpha
На котором можно написать эмулятор системы команд Тунгуски...
Внутри троичный сигнал будет состоять из двух двоичных:
00 - O (zero)
10 - N (negative)
01 - P (positive)
11 - X (exception or fatal error)
Если в качестве исходных схем использовать схемы для тримулятора, то там четвёртое значение - это Z (disconnected).
Я думаю, что сначала я всё таки сделаю первый вариант - непосредственно на языке схем Xilinx. Второй же вариант подразумевает наличие некоего конвертера из схем тримулятора в VHDL (что вполне возможно сделать, но требует некоторого времени).
UPDATE: Ниже приаттачена версия VHDL библиотеки v1.0 от 6 июля 2018 года:
Lavr wrote:Т.е. это будет чисто двухпроводная троичка безо всяких "мухлей" с высокоимпедансным состоянием или же резистивным делителем между двумя выводами? (обсуждали мы такие варианты...)
На CPLD/FPGA наверное непросто будет эти "мухли" реализовать (если вообще возможно), так что я в лоб иду - 2 провода на трит и внутри, и снаружи...
Вроде возможно средствами VHDL наружу подавать третье состояние (для девайсов, которые это умеют) - т.е. по идее можно сократить количество используемых выходов вдвое...
https://www.ternary-computing.com/index.php?page=1
Изготовители данного девайса заявляют, что вычислительная мощность составляет 278 миллионов коммерческих 32bit процессоров:
We have achieved amazing results, the capacity of our CPU is more than 278 billion times greater than a commercial 32-bit CPU.
Если это хоть в некоторой степени правда, то это указывает на большие перспективы троичной СС даже при реализации на основе двоичной FPGA схемы. Неплохо было бы проверить всё это.
jefffree wrote:https://www.ternary-computing.com/index.php?page=1
Изготовители данного девайса заявляют, что вычислительная мощность составляет 278 миллионов коммерческих 32bit процессоров:
We have achieved amazing results, the capacity of our CPU is more than 278 billion times greater than a commercial 32-bit CPU.
Если это хоть в некоторой степени правда, то это указывает на большие перспективы троичной СС даже при реализации на основе двоичной FPGA схемы. Неплохо было бы проверить всё это.
Понятно, что это двоичная FPGA схема. Вопрос в том, действительно ли переход на троичную СС значительно повышает вычислительную мощность, и насколько значительно...
Понятно, что это двоичная FPGA схема. Вопрос в том, действительно ли переход на троичную СС значительно повышает вычислительную мощность, и насколько значительно...
В данном случае основание - двоичная система. А рабочая среда, троичная система, фреймворк в ней же - типа того .Так или иначе преобразование происходит что уменьшает вообще любую мощность вычислений. Это сжирание аппаратных ресурсов заточенных изначально под другую систему.
Если от этого абстрагироваться и взять математические системы(двоичную и троичную) и поставить вопрос не о мощности вычислений, а об эффективности, то тут всё сведётся к задаче Фибонначи "о весах"! Решение этой задачи не имеет абсолютного ответа для всего. Минимум там два вывода , что в одном случае двоичная система оптимальна, в другом - троичная!
С т.з. современной математики оптимальная система счисления должна иметь в основании константу е(2.718....). Но .т.к. это не целочисленное значение то такая система фантастически неудобоварима восприятием и прочим.