Свою НЕхитрую идею я уже вроде озвучивал. Никакой общей памяти, никаких арбитров, отдельные процессоры со своими изолированными адресными пространствами должны обмениваться сообщениями и при необходимости данными через порты, для скорости применить ПДП. Думаю, это сильно увеличит надёжность ПО, упростит отладку, позволит проще наращивать число процессоров.petrenko wrote:А может у кого есть какие хитрые идеи на сей счёт ?
Двухпроцессорная система на микропроцессорах Intel 8080.
Moderator: Shaos
-
VituZz

- God
- Posts: 1343
- Joined: 13 Nov 2010 04:06
-
petrenko
- Doomed
- Posts: 598
- Joined: 10 Mar 2012 16:21
- Location: РФ
Это то как раз очевидно.b2m wrote:Самое простое - аппаратный порт, доступный обоим процессорам, после чтения из которого он устанавливается в 1, после записи - сбрасывается в ноль. Если считали ноль, значит мы главные и имеем право менять семафоры, события и др. элементы синхронизации в памяти.petrenko wrote:А может у кого есть какие хитрые идеи на сей счёт ?
Причём неважно, порт в пространстве ввода-вывода или в пространстве памяти или одна ячейка памяти "хитрая".
Суть вопроса именно в команде с сигналом "LOCK" на период обмена ( просто считывание не подходит, надеюсь всем ясно, почему именно ? ) именно с данным портом/ячейкой.
А спрошу ка я..
Люди добрые, кто может дать "разтактовочку/разцикловочку" команды XTH ( это eXchange_sTack_word_&_HL_register_pair которая ) ?
А я подумаю ещё хорошенько, как к этой ( IMHO наиболее подходящей - нет, пожалуй, даже вообще единственной подходящей ) команде "прикошачить" сигнал "LOCK"..
-
HardWareMan

- Banned
- Posts: 2139
- Joined: 20 Mar 2005 13:41
- Location: От туда
-
Lavr

- Supreme God
- Posts: 17043
- Joined: 21 Oct 2009 08:08
- Location: Россия
Извини, вопрос у меня немного наивный и слегка не в тему - а где посмотреть точныеpetrenko wrote:...команды XTH ( это eXchange_sTack_word_&_HL_register_pair которая )
расшифровки аббревиатур команд?
Я в принципе их практически все знаю, но в правильности некоторых - просто сомневаюсь...
Хотелось бы для себя окончательно и бесповоротно это навсегда уточнить.
В общем-то твоя команда тоже - XTHL, а не XTH - это чисто к слову, если для i8080...
iLavr
-
petrenko
- Doomed
- Posts: 598
- Joined: 10 Mar 2012 16:21
- Location: РФ
Да кто их знает.. 
У самого Intel-а есть и XTH и XTHL в описаниях - похоже что трёхбуквенные варианты были в тех случаях, когда кросс-системы были нежными и капризными и не "переваривали" более трёх буковок..
А так - совершенно всё равно, как ни обозвать команды - у Z80 например совсем другие мнемоники, но выполняет он все коды 8080 в конце концов.
( А ещё есть как кросс- , так и просто ассемблеры, которые допускают задание синонимов. )
Считаю мелкие разночтения не приводящие к ошибкам несущественными и препочитаю не обращать на таковые сугубого внимания.
Изходя из имеющихся данных и множества размышлений попробую следующую последовательность :
Если <считанный по ШД байт ==11100011bin во время M1> ,то в течении следующего M2/T1 устанавливается сигнал LOCK ;
далее, если <adr==FFFE во время M2/T1,M2/T2>, то сигнал LOCK удерживается во время следующих M2/T2,M2/T3,M3/T1,M3/T2,M3/T3,M4/T1,M4/T2,M4/T3,M5/T1,M5/T2,M5/T3,M5/T4,M5/T5 при этом если <adr==FFFE> "не готов", то есть занят, то подаётся "READY", вставляющий "WAIT" в M2 - то есть ждём завершения "локнутого" обмена другого процессора с ячейками с adr==FFFE и adr==FFFF
Флагом занятости семафора неким процессором будет являться бит, позиция которого соответствует позиции того процессора.
Если более одного флага - делаем всеобщий "ахтунг" типа системной изключительной ситуации.
Если все свободны - занимаем и работаем с массивом в общем "засемафореном" пространстве памяти, после чего освобождаем.
Почему с массивом ? Да просто с несколькими байтами проще и надёжнее именно как предлагал "VituZz"- посылать сообщения.
А вот массивы как раз лучше в общей памяти держать.
Собственно Intel всё сие и в гораздо лучшем виде сделало в 8086.
И были десяти-процессорные комплексы на шине "мультибус".
Но мы то тут "апгрейдим" 8080 для развлекухи, так что придётся и саночки потаскать в горку, не так ли ?
У самого Intel-а есть и XTH и XTHL в описаниях - похоже что трёхбуквенные варианты были в тех случаях, когда кросс-системы были нежными и капризными и не "переваривали" более трёх буковок..
А так - совершенно всё равно, как ни обозвать команды - у Z80 например совсем другие мнемоники, но выполняет он все коды 8080 в конце концов.
( А ещё есть как кросс- , так и просто ассемблеры, которые допускают задание синонимов. )
Считаю мелкие разночтения не приводящие к ошибкам несущественными и препочитаю не обращать на таковые сугубого внимания.
Дякуэм.HardWareMan wrote:Доставлено.

Изходя из имеющихся данных и множества размышлений попробую следующую последовательность :
Если <считанный по ШД байт ==11100011bin во время M1> ,то в течении следующего M2/T1 устанавливается сигнал LOCK ;
далее, если <adr==FFFE во время M2/T1,M2/T2>, то сигнал LOCK удерживается во время следующих M2/T2,M2/T3,M3/T1,M3/T2,M3/T3,M4/T1,M4/T2,M4/T3,M5/T1,M5/T2,M5/T3,M5/T4,M5/T5 при этом если <adr==FFFE> "не готов", то есть занят, то подаётся "READY", вставляющий "WAIT" в M2 - то есть ждём завершения "локнутого" обмена другого процессора с ячейками с adr==FFFE и adr==FFFF
Флагом занятости семафора неким процессором будет являться бит, позиция которого соответствует позиции того процессора.
Если более одного флага - делаем всеобщий "ахтунг" типа системной изключительной ситуации.
Если все свободны - занимаем и работаем с массивом в общем "засемафореном" пространстве памяти, после чего освобождаем.
Почему с массивом ? Да просто с несколькими байтами проще и надёжнее именно как предлагал "VituZz"- посылать сообщения.
А вот массивы как раз лучше в общей памяти держать.
Собственно Intel всё сие и в гораздо лучшем виде сделало в 8086.
И были десяти-процессорные комплексы на шине "мультибус".
Но мы то тут "апгрейдим" 8080 для развлекухи, так что придётся и саночки потаскать в горку, не так ли ?
-
Lavr
- Supreme God
- Posts: 17043
- Joined: 21 Oct 2009 08:08
- Location: Россия
-
petrenko
- Doomed
- Posts: 598
- Joined: 10 Mar 2012 16:21
- Location: РФ
-
Shaos

- Admin
- Posts: 25124
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
На самом деле если 8080 трогает шину только один раз на 3-4 такта, то теоретически можно напихать до 4 процессоров без существенной потери производительности, которые будут тормозить друг-друга через арбитра шины, если цикл чтения-записи попадёт на один и тот же такт - надо чтоли прикинуть веротяность конфликта и соответственно торможения в этом случае...Lavr wrote:В процессе просеивания частым бреднем гугля сети, нашел я и ещё один весьма
интересный для меня материал:
Двухпроцессорная система на микропроцессорах Intel 8080.
Честно говоря, это первая реальная схема такого плана, которую я вижу...
Собственно говоря, эта система ничего определённого не делает, а рассматривают
её как раз с точки зрения вопроса - как создать многопроцессорную
систему на любимых нами Intel 8080.
И решение для меня просто необычно - они применили арбитр шины 74F786
(4-bit asynchronous bus arbiter).
Я про такой, каюсь, даже не знал, поэтому быстренько накачал datasheet 74F786.pdf...
Ну и вот что пишут в самом материале:Используя арбитр шины 74F786, можно создать систему, в которой присутствует два процессора Intel 8080, разделяющих одну общую шину для доступа к памяти. В отличие от простой системы с одним активным устройством на шине (процессором), здесь ситуация осложняется тем, что нужно разделить время обращений к шине от активных устройств, чтобы они друг другу не мешали. Одного арбитра для этого недостаточно, т.к. он только вырабатывает сигналы разрешения доступа, но не производит никаких действий по отключению шин активных устройств от системной шины. Кроме того, требуется схема выработки управляющих сигналов для памяти и регистров портов ввода/вывода, если они есть.
Арбитр шины 74F786 – служит для распределения времени доступа к системной шине. Входные запросы формируются из сигналов чтения/записи памяти, поступающих от системных контроллеров. Выходы разрешения BG подключены к входам BUSEN системных контроллеров, что позволяет подключать локальные шины данных процессоров к памяти в нужный момент. Так же эти сигналы, пройдя через инвертор, попадают на вход READY процессоров, что дает возможность подождать, пока доступ к памяти не будет разрешен.
-
vinxru
- Retired
- Posts: 587
- Joined: 27 Mar 2013 04:55
- Location: 62.192.229.16
Процессор RD и WR держит два такта.
Но даже это не мешает работать еще быстрее. Процессор выставил RD, мы подключаем шину адреса этого процессора к памяти, ждем требуемое памятью время (вот у меня чипина лежит 10нс), защелкиваем значение в регистре подключенном к процессору. И память больше не нужна.
А RD у процессора будет висеть еще 1000нс.
C WR еще проще. Просто уменьшаем его длительность до 10 нс.
Но даже это не мешает работать еще быстрее. Процессор выставил RD, мы подключаем шину адреса этого процессора к памяти, ждем требуемое памятью время (вот у меня чипина лежит 10нс), защелкиваем значение в регистре подключенном к процессору. И память больше не нужна.
А RD у процессора будет висеть еще 1000нс.
C WR еще проще. Просто уменьшаем его длительность до 10 нс.
-
Lavr
- Supreme God
- Posts: 17043
- Joined: 21 Oct 2009 08:08
- Location: Россия
Shaos wrote:Печальная история про бессмысленную и от всех скрываемую схему на двух 8080, работающихShaos wrote:Читаем внимательно, что я написал:Перевожу на более понятный русский - "аффтар пеши в другом топеке"Shaos wrote:Про подвешивание второго проца, пока первый елозит по общей памяти - это не сюда
Тут у нас полностью прозрачное обращение к памяти обоих процов одновременно...
по очереди, теперь располагается в другом месте:
viewtopic.php?t=10136
Да схема-то и была, и есть по сей день. Я успел её ухватить тогда с указанного мной адреса.Shaos wrote:А была ли схема то? Вот в чём вопрос...
Но, глядя на твои гнусные диктаторские замашки, - я несколько разобиделся, и схема
жаждущих адресатов, получается, что и не достигла...
Но поскольку наблюдаю в тебе положительные перемены, выразившиеся в безобразном
отношении к закидыванию форума гнусными картинками, в чем и я, признаюсь - грешен,
поучаствовал, считаю нужным покидаться и полезной картинкой с её описанием, по
которому я понял в общих чертах, как многопроцессорные системы строятся, и посему
к этой теме слегка поостыл...
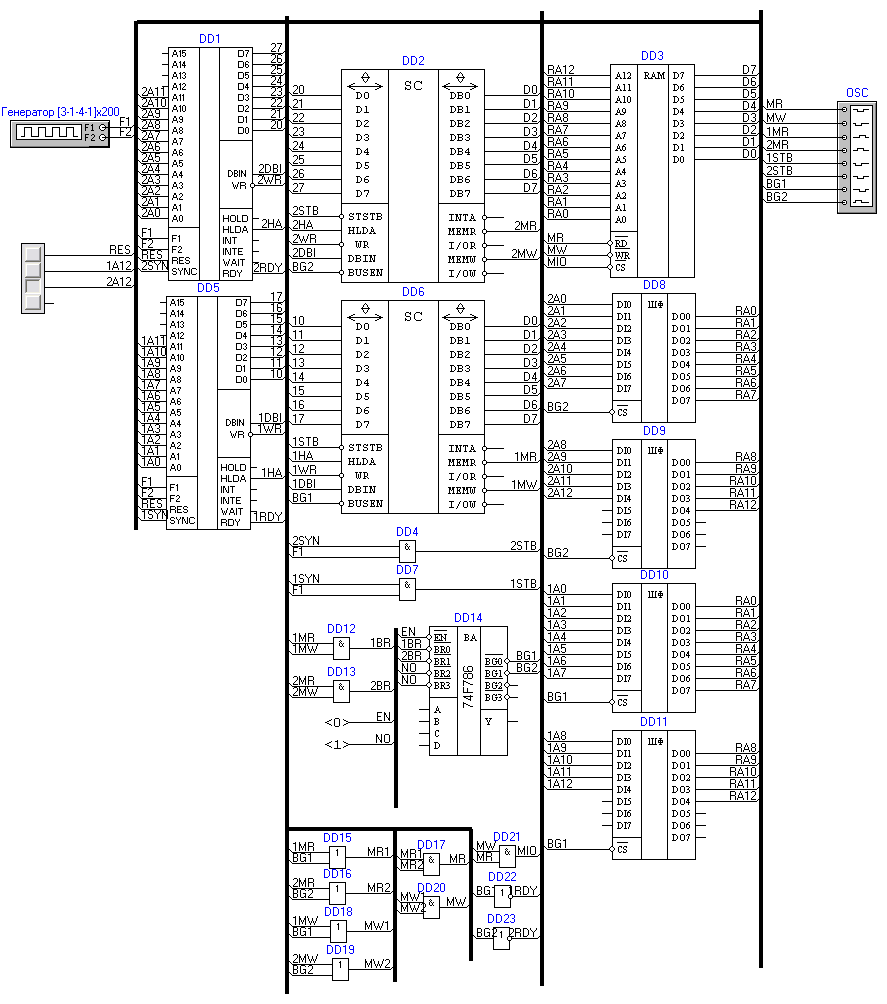
Двухпроцессорная система
Используя микросхему арбитра шины 74F786 , можно создать систему, в которой присутствует два процессора Intel 8080, разделяющих одну общую шину для доступа к памяти. В отличие от простой системы с одним активным устройством на шине (процессором), здесь ситуация осложняется тем, что нужно разделить время обращений к шине от активных устройств, чтобы они друг другу не мешали. Одного арбитра для этого недостаточно, т.к. он только вырабатывает сигналы разрешения доступа, но не производит никаких действий по отключению шин активных устройств от системной шины. Кроме того, требуется схема выработки управляющих сигналов для памяти и регистров портов ввода/вывода, если они есть.
В собранной схеме присутствуют следующие элементы:
1. Два процессора Intel 8080. Чтобы как-то отличить их при параллельной работе, старший разряд их шин адреса подключен не к процессору, а зафиксирован в одном положении («0» для одного процессора, «1» для другого), иначе они будут выполнять одну и ту же программу. В реальных системах так поступать не следует, т.к. процессоры никак не могут обратиться к одной и той области памяти. В нашем случае это не важно, т.к. мы проверяем саму возможность параллельной работы и работоспособность арбитра и схем сопровождения;
2. Два системных контроллера ВК28 (Intel 8228) – по одному на процессор. Служат для выработки управляющих сигналов и управления шиной данных;
3. Модуль ОЗУ на 8 килобайт;
4. Четыре односторонних шинных формирователя (по два на процессор) – служат для подключения адресных выходов процессоров к шине адреса памяти в моменты доступа к ней. В остальное время шины должны быть отключены, чтобы процессоры не мешали друг другу, одновременно выставляя адрес на одну и ту же шину;
5. Арбитр шины 74F786 – служит для распределения времени доступа к системной шине. Входные запросы формируются из сигналов чтения/записи памяти, поступающих от системных контроллеров. Выходы разрешения BG подключены к входам BUSEN системных контроллеров, что позволяет подключать локальные шины данных процессоров к памяти в нужный момент. Так же эти сигналы, пройдя через инвертор, попадают на вход READY процессоров, что дает возможность подождать, пока доступ к памяти не будет разрешен;
6. Также есть несколько базовых логических элементов для формирования управляющих сигналов.
iLavr
-
Lavr
- Supreme God
- Posts: 17043
- Joined: 21 Oct 2009 08:08
- Location: Россия
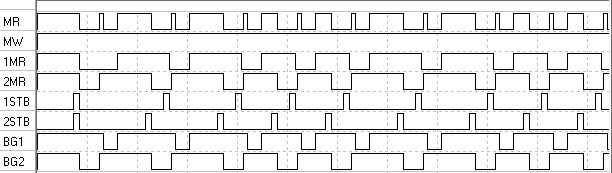
Временные диаграммы работы здесь следующие:
-----------
-----------
Первые два канала анализатора показывают состояние входов памяти RD и WR. Т.к. записи в память у нас нет, сигналы запроса доступа в шине будут совпадать с сигналами MR, приходящими от системных контроллеров (следующие два канала). Еще два канала показывают состояние сигналов ST.STB, т.е. фактически положение во времени циклов команд. Наконец, последние два канала – состояние выходов разрешения арбитра.
Видно, что при первой попытке чтения памяти оба процессора выставили запрос одновременно. Арбитр выбрал запрос второго процессора и выставил на BG2 сигнал низкого уровня. В это время вход READY процессора 1 неактивен, поэтому процессор ждет, пока ему не предоставят доступ к шине. Второй процессор в это время производит чтение из памяти. Наконец, доступ предоставляется первому процессору.
В дальнейшем задержки уже не наблюдаются, т.к. выполненные первым процессором такты ожидания привели к «разности фаз» исполнения команд, поэтому в дальнейшем запросы не перекрывались во времени. Поэтому в течение последующей работы процессоры выполняли свои программы действительно одновременно. Т.е. шина памяти здесь не является узким местом, в отличие от реальных систем, где требования процессоров намного выше возможности памяти (что приводит к необходимости использования кэш-памяти процессоров).
iLavr
-
Shaos
- Admin
- Posts: 25124
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
в орионе со спецом вроде ничего не защёлкивали - проц успевал читать за один такт?...vinxru wrote:Процессор RD и WR держит два такта.
Но даже это не мешает работать еще быстрее. Процессор выставил RD, мы подключаем шину адреса этого процессора к памяти, ждем требуемое памятью время (вот у меня чипина лежит 10нс), защелкиваем значение в регистре подключенном к процессору. И память больше не нужна.
А RD у процессора будет висеть еще 1000нс.
C WR еще проще. Просто уменьшаем его длительность до 10 нс.
-
vinxru
- Retired
- Posts: 587
- Joined: 27 Mar 2013 04:55
- Location: 62.192.229.16
-
HardWareMan
- Banned
- Posts: 2139
- Joined: 20 Mar 2005 13:41
- Location: От туда
