Это обычная инженерная банальщина : есть ток, есть допустимое падение напряжения - получаем либо необходимую ширину шин питания и земли либо медный провод поверх дороги. Из-за развязки по питанию рядом с потребителями скин-эффектом можно принебречь.MC68k wrote:60 ампер это не шутка - рэйлы питания надо серьезные делать и землю не абы как прокладывать иначе не взлетит. пусть не 60, пусть половина - 30ампер. все равно немало. я так понимаю, что осциллограф есть. ткнись им на землю в орионе - крокодильчиком около разъема питания, а щупом потыкай по земляной шине. удивительно, правда? а там всего 1,5 ампера гуляет.
nedoPC-580 (SMP на 5 процессорах КР580ВМ80А)
Moderator: Shaos
-
BarsMonster

- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
-
Lavr

- Supreme God
- Posts: 17034
- Joined: 21 Oct 2009 08:08
- Location: Россия
И некоторые мысли по распараллеливанию задачи я изложу, тем более,Lavr wrote:А я тут почитал материалы по "Эльбрусу" и очень вот в этом тезисе усомнился.ntil wrote:Распараллеливание задая на треды - это не прерогатива ОС. ОС только обеспечивает механизм управления многими задачами - многозадачность, многотредовость.
...
б) оптимизирующего компилятора, который сам параллелит все, что можно. Поддержка распарралеливания в ОС "на лету" - не оптимально - выгоднее это сделать один раз компилятором, чем делать при каждом запуске приложения.
что материалы по "Эльбрусу" меня в этой мысли укрепили.
Ну первое - это конфигурация:
На мой взгляд, чтобы ориентироваться на практическое воплощение кострукции,
процессоров должно быть 4.
Графический проц, процессор для задач ввода вывода и два обычных проца, один
из которых - ведущий и может управлять другими тремя.
Он же "системный", он же "супервизор" и т.д., он же отвечает за оптимизирующую
компиляцию.
У всех процессоров своя память, своя копия ОС с вызовами API, и общая для всех
область системных переменных и обмена данными.
Примерно так... по ходу дела можно уточнять.
Теперь скажу сразу - как перекомпилировать готовую программу в кодах процессора
я хоть и немного представляю, но - с большим трудом.
Но в примерах для "Эльбруса" тоже не решают эту задачу в кодах, а компилируют в
коды из текста на С.
С для наших процессоров существует, но существует и более популярный для
них Basic. И я совсем не зря компиляторами Basic-а вот здесь интересуюсь...
Вот как раз в момент компиляции с языка высокого уровня распараллеленный
код и можно разнести по процессорам, разложив каждому из них в его память.
При компиляции с Basic-а процессы хорошо различимы: inkey$, input - процессору ВВ,
line, pset, box и др. - графическому процессору, основную программу - третьему процессору,
и четвертый - обеспечивает координацию работы всех процессоров и занимается работой ОС.
То есть обслуживает прерывания, организует информацию в общей области, очередь
сообщений и т.п.
Примено как-то так...
Естественно ОС должна быть также написана с учетом разделения задач на процессоры.
Готовую старую ассемблерную программу можно выполнять на одном процессоре.
Если он пользуется системными вызовами, то многопроцессорное исполнение работает.
Если он, такой урод, лезет согласно коду программы в порты и видеопамять сам -
да и фиг с ним, пусть лезет!
Конце-концов старые программы-игры и рассчитаны на один процессор со всеми
трюками в кодах и в ускорении, как и распараллеливании - не нуждаются.
Другое дело что старых задач можно запустить в параллель - 3 штуки, т.к. независимых
равноправных процессоров у нас - 3.
А для переключения задач - можно переключать экран по страницам памяти.
Аппаратно - эта процедура вполне понятная.
iLavr
-
Lavr
- Supreme God
- Posts: 17034
- Joined: 21 Oct 2009 08:08
- Location: Россия
Ну сейчас все скажут - "слишкамногобукав", "стена букав - стена плача", поэтому
пару слов о практическом тестировании этих идей я также расскажу.
Ну прежде всего, я долго серьёзно работал на самодельном "Специалисте_МХ",
у которого вот такая карта памяти:
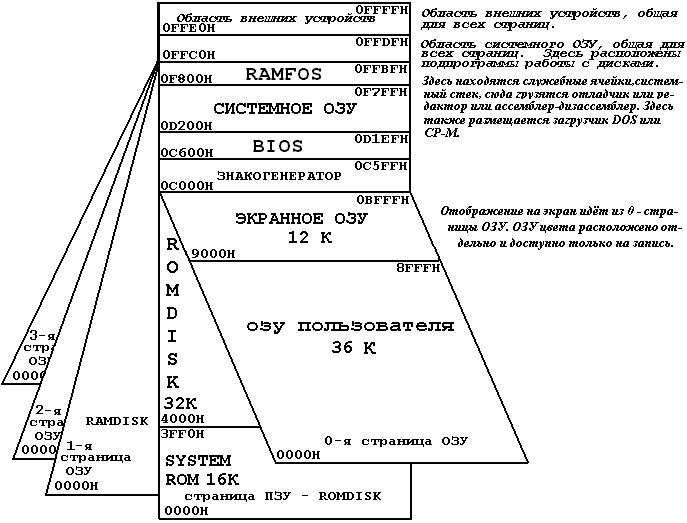
(Интересно, что я и нарисовал эту картинку в древние времена для себя, и очень удивился,
когда обнаружил её в интернете! Но догадался потом, что от Вити Пыхонина утекло... )
)
Так вот, когда мы с другом купили СР/М в Воронеже, мы стали тужиться адаптировать её
на наши "Специалисты_МХ", и стала выясняться такая подробность, что СР/М вроде как получается
работает не из 0-страницы ОЗУ (ОЗУ пользователя), а из 1-страницы ОЗУ!
Меня это феноменально удивило и я решил проделать следующий опыт: поскольку 1-страница ОЗУ
в "Специалисте_МХ" - это квазидиск, я оставил его свободным, а с адреса 0000Н разместил коды вот
этой игрушки:
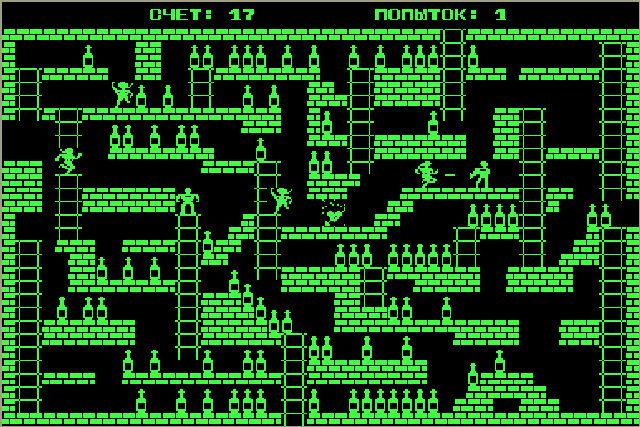
Мы эту игрушку обсуждали в курилке, и она интересна тем, что ей нужны только адреса портов
и начала экрана. Системных вызовов она не использует, а ещё она была использована поскольку я
в неё мог сыграть уровня 3-4 не глядя на экран...
Порты-то из 1-страницы ОЗУ - доступны, а экранное ОЗУ - оно только в 0-странице ОЗУ - в ОЗУ
пользователя!
В общем, ориентируясь по звукам, я в неё без экрана поиграл, вышел в систему и сделал перенос
области экрана 9000-BFFFh из 1-страницы ОЗУ в 0-страницу ОЗУ вот этим монитором (он умеет
делать перемещения блоков между страницами.):
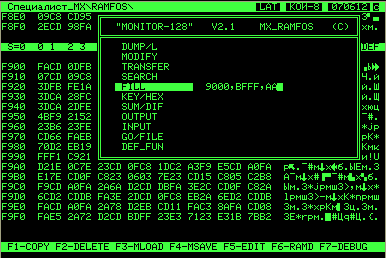
И я скажу честно был удивлён, когда увидел скриншот работавшей игры как на картинке выше!
Вот тут я впервые задумался, что можно сделать многозадачность как в Венде - запустить 2 задачи
в разных страницах и давать им кванты времени процессора.
А можно и каждой странице предоставить свой процессор!
Окончательно я поверил в возможность этой идеи, когда ковырялся в структуре интерпретаторов
Васика - там просто по структуре кода просится раздавать свои задачи разным процессорам -
графическому и ВВ.
Ну и последнее что меня убедило в аппаратной возможности многопроцессорности - это пусть и
слегка наивные опыты Шурика с соединением 2-х компьютеров.
Так что, исходя из этих опытов и предпосылок, 4-процессорная система не кажется мне чрезмерно
сложной. Я так представляю, что нам надо прийти к некоторым общим соглашениям по структуре на
аппаратном уровне и пробовать отдельные решения в софте.
Это не так всеобъемлюще и абстрактно-непонятно, как мы излагаем в теории и блок-схемах, и я бы
рискнул начать это моделировать в среде "Proteus", вот только процессора у меня там нет...
А с CEDAR Logic Simulator всё оказалось не так радужно, как хотелось...
пару слов о практическом тестировании этих идей я также расскажу.
Ну прежде всего, я долго серьёзно работал на самодельном "Специалисте_МХ",
у которого вот такая карта памяти:
(Интересно, что я и нарисовал эту картинку в древние времена для себя, и очень удивился,
когда обнаружил её в интернете! Но догадался потом, что от Вити Пыхонина утекло...
Так вот, когда мы с другом купили СР/М в Воронеже, мы стали тужиться адаптировать её
на наши "Специалисты_МХ", и стала выясняться такая подробность, что СР/М вроде как получается
работает не из 0-страницы ОЗУ (ОЗУ пользователя), а из 1-страницы ОЗУ!
Меня это феноменально удивило и я решил проделать следующий опыт: поскольку 1-страница ОЗУ
в "Специалисте_МХ" - это квазидиск, я оставил его свободным, а с адреса 0000Н разместил коды вот
этой игрушки:
Мы эту игрушку обсуждали в курилке, и она интересна тем, что ей нужны только адреса портов
и начала экрана. Системных вызовов она не использует, а ещё она была использована поскольку я
в неё мог сыграть уровня 3-4 не глядя на экран...
Порты-то из 1-страницы ОЗУ - доступны, а экранное ОЗУ - оно только в 0-странице ОЗУ - в ОЗУ
пользователя!
В общем, ориентируясь по звукам, я в неё без экрана поиграл, вышел в систему и сделал перенос
области экрана 9000-BFFFh из 1-страницы ОЗУ в 0-страницу ОЗУ вот этим монитором (он умеет
делать перемещения блоков между страницами.):
И я скажу честно был удивлён, когда увидел скриншот работавшей игры как на картинке выше!
Вот тут я впервые задумался, что можно сделать многозадачность как в Венде - запустить 2 задачи
в разных страницах и давать им кванты времени процессора.
А можно и каждой странице предоставить свой процессор!
Окончательно я поверил в возможность этой идеи, когда ковырялся в структуре интерпретаторов
Васика - там просто по структуре кода просится раздавать свои задачи разным процессорам -
графическому и ВВ.
Ну и последнее что меня убедило в аппаратной возможности многопроцессорности - это пусть и
слегка наивные опыты Шурика с соединением 2-х компьютеров.
Так что, исходя из этих опытов и предпосылок, 4-процессорная система не кажется мне чрезмерно
сложной. Я так представляю, что нам надо прийти к некоторым общим соглашениям по структуре на
аппаратном уровне и пробовать отдельные решения в софте.
Это не так всеобъемлюще и абстрактно-непонятно, как мы излагаем в теории и блок-схемах, и я бы
рискнул начать это моделировать в среде "Proteus", вот только процессора у меня там нет...
А с CEDAR Logic Simulator всё оказалось не так радужно, как хотелось...
iLavr
-
Shaos

- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Ну ещё на стандартном (немодифицированном) ZX-спектруме в начале 90-х народ мог делать резидентные задачи, которые к примеру рисовали на экране некую картинку, при этом можно было продолжать пользоваться бейсиком, писать и запускать бейсик-программки и т.д. Поэтому как раз не проблема иметь несколько тредов на одном процессоре, а проблема иметь процессы на разных процессорах, работающих с общей памятью. Я тут подумал, что чисто программно мьютексы не сделать - всё равно будет вероятность того, что к ячейке с состоянием мьютекса процессы обратятся одновременно и одновременно же попробуют его залочить. Поэтому в системе должен быть как минимум один аппаратный мьютекс, который будет закрывать доступ к программным мьютексам, причём закрывать серъёзно - т.е. останавливая все процессоры кроме одного (даже если обращается больше одного должен быть выбран один). Например путём вывода в некий порт программа будет говорить железяке, что она хочет поработать с одним из мьютексов (захватить или освободить), в этот момент железяка остановит все процессоры кроме просящего (либо первого из просящих), далее программа устанавливает (и идёт дальше либо запоминает что она должна локнуться) либо сбрасывает мьютекс и пишет в другой порт чтобы сигнализировать о том, что работа с мьютексами закончена - далее железяка отпускает все процессы, а просящий процесс либо висит на программном локе (ожидая когда программный мьютекс отпустят при этом ос может отдавать управление другим тредам на этом же процессоре), либо идёт дальше - в зависимости от результата лочки-анлочки программного мьютекса. Вобщем как-то так...
P.S. На 8080 полноценно переключать контексты в пределах одного процессора будет проблематично т.к. на 8080 нельзя непосредственно прочитать значение регистра SP... Хотя почему нельзя? Можно! Вот тут Lvar писал как - LXI H,0; DAD SP; и даже разработал концепцию самоперемещаемых программ : )
P.P.S. Вобщем постепенно вырисовывается у меня то, как это должно быть построено. 4 или 5 процов (пятый без доступа к общей памяти) и текстовый экран. Наверное совместимость со старым софтом таки будет - предлагаю CP/M-80, но задачи CP/M-80 нельзя будет переключать - только запускать и гасить (хотя почему нельзя?). Потом будет класс переключаемых задач, написанных по строгим правилам - использование документированных функций и расположение кода и стека в определённых местах памяти...
P.S. На 8080 полноценно переключать контексты в пределах одного процессора будет проблематично т.к. на 8080 нельзя непосредственно прочитать значение регистра SP... Хотя почему нельзя? Можно! Вот тут Lvar писал как - LXI H,0; DAD SP; и даже разработал концепцию самоперемещаемых программ : )
P.P.S. Вобщем постепенно вырисовывается у меня то, как это должно быть построено. 4 или 5 процов (пятый без доступа к общей памяти) и текстовый экран. Наверное совместимость со старым софтом таки будет - предлагаю CP/M-80, но задачи CP/M-80 нельзя будет переключать - только запускать и гасить (хотя почему нельзя?). Потом будет класс переключаемых задач, написанных по строгим правилам - использование документированных функций и расположение кода и стека в определённых местах памяти...
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Не боись - скоро будет новый опенсорцный эмуляторLavr wrote:Это не так всеобъемлюще и абстрактно-непонятно, как мы излагаем в теории и блок-схемах, и я бы
рискнул начать это моделировать в среде "Proteus", вот только процессора у меня там нет...
А с CEDAR Logic Simulator всё оказалось не так радужно, как хотелось...
Вобщем иметь свой набор задач для каждого процессора - это скушно. Давайте иметь ОБЩИЙ набор задач, способных восстанавливаться на ЛЮБОМ процессоре!
Итак, делим адресное пространство на 4 окна по 16Кб - в первых трёх окнах имеем возможность подключения разных страниц большого общего ОЗУ (скажем размером 512К), причём каждый процессор может подключать их себе по разному. А последнее окно делим по хитрому:
Code: Select all
#C000...#C7FF - ОЗУ 2К (у каждого процессора своё - всего 8К)
#C800...#CFFF - ОЗУ 2К (общее)
#D000...#FFFF - ПЗУ 12К (общее)
P.S. Пятый процессор может обратиться к общему ОЗУ 2К, что должно приводить к немедленному останову первых четырёх процессоров (это должно происходить только в экстренных случаях). У этого пятого процессора будет 8К ОЗУ, 8K ПЗУ и гнездо для сменного картриджа 8К ПЗУ ( только что придумал : ). Кроме того в железяке предполагается текстовый видеомодуль с 2К видео-озу (пока предполагается мой старый NedoText) - вот мы и получили дополнительные 26К
P.P.S. Вот пятый процессор и может заниматься контролем доступа к мьютексам, функциями вач-дога, вводом-выводом и т.д.
-
Lavr
- Supreme God
- Posts: 17034
- Joined: 21 Oct 2009 08:08
- Location: Россия
Вот не нравится мне мьютексы, ну хоть убей... и в литературе пишут, что они не панацея...
Хотя, вероятно, тебе и виднее, но я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
И у меня к тебе есть скромное предложение... раз уж ты взялся за эмулятор, а это дело не быстрое,
но модели что i8080, что Z80 мы знаем довольно неплохо и разные исходники и прототипы у нас есть,
может быть, ты взглянул бы разочек, как оформляется dll-модель для "Protezus"?
И модель процессора хотя бы черновую набросал?
А то из меня фиговый программист на Цэ, а по прототипу я доточить до ума много что могу...
Так от меня в новом опенсорцном эмуляторе - пользы никакой, а иначе я бы прикидки многопроцессорной
системы поделал бы пока...
Хотя, вероятно, тебе и виднее, но я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
И у меня к тебе есть скромное предложение... раз уж ты взялся за эмулятор, а это дело не быстрое,
но модели что i8080, что Z80 мы знаем довольно неплохо и разные исходники и прототипы у нас есть,
может быть, ты взглянул бы разочек, как оформляется dll-модель для "Protezus"?
И модель процессора хотя бы черновую набросал?
А то из меня фиговый программист на Цэ, а по прототипу я доточить до ума много что могу...
Так от меня в новом опенсорцном эмуляторе - пользы никакой, а иначе я бы прикидки многопроцессорной
системы поделал бы пока...
iLavr
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
512K это 32 страницы по 16К - предположим, что каждая задача может занимать одну страницу. Если считать задачу потенциально совместимой с CP/M-80, то первые 256 байт должны быть отведены под системные переменные, причём область #0050...#005F не используется в CP/M-80 v2.2 - вот туда мы и будем сохранять контекст задачи, а именно текущее состояние регистров, а также номер процесса:
Вот код передачи управления на восстановленный процесс:
Вроде должно полететь 
P.S. А вот код сохранения регистров для переключения контекста в обработчике прерываний (для начала думаю пусть прерывание будет по таймеру 10 раз в секунду):
P.S. 28 августа добавил восстановление флага C по совету b2m
Code: Select all
#0050 - #AA если страница занята процессом
#0051 I - порядковый номер процесса
#0052 W1 - порядковый номер страницы, подключенной в окно #4000...#7FFF
#0053 W2 - порядковый номер страницы, подключенной в окно #8000...#BFFF
#0054 PL - младший байт сохранённого PC
#0055 PH - старшинй байт сохранённого PC
#0056 SL - младший байт сохранённого SP
#0057 SH - старшинй байт сохранённого SP
#0058 L - регистр L
#0059 H - регистр H
#005A E - регистр E
#005B D - регистр D
#005C C - регистр C
#005D B - регистр B
#005E F - регистр F
#005F A - регистр A
Code: Select all
LXI SP,#0054 ; ready to load registers from memory
POP B ; BC=PC
POP H ; HL=SP
; store PC to process stack:
DCX H
MOV M,B
DCX H
MOV M,C
POP B ; BC=HL
; store HL to process stack:
DCX H
MOV M,B
DCX H
MOV M,C
POP D ; load DE
POP B ; load BC
POP PSW ; load AF
SPHL ; HL->SP
POP H ; load HL
RET ; load PC
P.S. А вот код сохранения регистров для переключения контекста в обработчике прерываний (для начала думаю пусть прерывание будет по таймеру 10 раз в секунду):
Code: Select all
SHLD #0058 ; save HL
POP H ; HL=PC
SHLD #0054 ; save PC
LXI H,0
JC SETC
DAD SP ; HL=SP and clear C
JMP GOSTACK
SETC:
DAD SP ; HL=SP and then set C
STC ; set flag C
GOSTACK:
SHLD #0056 ; save SP
LXI SP,#0060
PUSH PSW ; save AF
PUSH B ; save BC
PUSH D ; save DE
; now switch context to another process
Last edited by Shaos on 28 Aug 2012 06:30, edited 6 times in total.
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Аппаратный арбитр может и поможет если мы имеем не более одного процесса на процессор, а если надо больше одного?... Хотя в этом случае можно просто запрещать прерывания на время работы в критической секции...Lavr wrote:Вот не нравится мне мьютексы, ну хоть убей...
Хотя, вероятно, тебе и виднее, но я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
.
Ну тут придётся ведь по тактам делать правдоподобное поведение, а в эмуле можно такие тонкости опустить....Lavr wrote: И у меня к тебе есть скромное предложение... раз уж ты взялся за эмулятор, а это дело не быстрое,
но модели что i8080, что Z80 мы знаем довольно неплохо и разные исходники и прототипы у нас есть,
может быть, ты взглянул бы разочек, как оформляется dll-модель для "Protezus"?
И модель процессора хотя бы черновую набросал?
А то из меня фиговый программист на Цэ, а по прототипу я доточить до ума много что могу...
Ну зато ты можешь код на асме 8080 писать и проверять - хоть прямо уже щасLavr wrote: Так от меня в новом опенсорцном эмуляторе - пользы никакой, а иначе я бы прикидки многопроцессорной
системы поделал бы пока...
Last edited by Shaos on 27 Aug 2012 20:00, edited 2 times in total.
-
BarsMonster
- Senior
- Posts: 126
- Joined: 21 Jul 2012 15:56
- Location: Zürich, Switzerland
Мютексы всем не нравятся. Но используют их не от хорошей жизни - они просто наиболее простые и надежные в реализации (и при правильном использовании - решают все проблемы с синхронизацией потоков).Lavr wrote:Вот не нравится мне мьютексы, ну хоть убей...
Хотя, вероятно, тебе и виднее, но я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
А реализовывая "аппаратный арбитр с приоритетами" поседеть можно будет.
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Мне 10 лет назад мьютексы тоже не нравились, но потом я понял, что без них никак и мне пришлось их полюбитьBarsMonster2 wrote:Мютексы всем не нравятся. Но используют их не от хорошей жизни - они просто наиболее простые и надежные в реализации (и при правильном использовании - решают все проблемы с синхронизацией потоков).Lavr wrote:Вот не нравится мне мьютексы, ну хоть убей...
Хотя, вероятно, тебе и виднее, но я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
А реализовывая "аппаратный арбитр с приоритетами" поседеть можно будет.
-
Lavr
- Supreme God
- Posts: 17034
- Joined: 21 Oct 2009 08:08
- Location: Россия
А мне кажется - это никчему и усложнение лишнее. Один процессор - один процесс.Shaos wrote:Аппаратный арбитр может и поможет если мы имеем не более одного процесса на процессор, а если надо больше одного?...Lavr wrote:...я бы решил эту проблему доступа процессоров к общей памяти
посредством аппаратного арбитра с настраиваемыми привелегиями...
Не забываем, что у нас процессоры - дряхлые стариканы...
Ну это просто ерунда схемотехнически для предлагаемой мною конструкции...BarsMonster2 wrote:А реализовывая "аппаратный арбитр с приоритетами" поседеть можно будет.
Ну не надо конструировать Венду на i8080 и Z80 - вот тут-то сами и повесимся
с этими мьютексами...
iLavr
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Кстати арбитр не поможет (точнее может и поможет, но с большими издержками) - он ведь просто будет пускать лишь один проц в общую память, а на самом деле в подавляющем большинстве случаев процы не будут друг другу мешать лазя в одну и туже память - защищать надо не всю память, а только отдельные её критические части, которые должен выявить и обозначить программист - поэтому автоматика тут как раз меньше всего нужна т.к. с ней КПД будет сильно ниже...
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Вобщем информация обо всех глобальных мьютексах будет храниться в общей непереключаемой памяти (#C800...#CFFF). Любой процесс может в любой момент прочитать состояние любого мьютекса, однако чтобы локнуть или анлокнуть мьютекс, надо будет уведомить супервизора, что процесс хочет зайти в критическую секцию - для этого можно обратиться к какому-то специальному адресу (упрощаем железо - портов нету), предварительно запретив прерывания:Shaos wrote:Я тут подумал, что чисто программно мьютексы не сделать - всё равно будет вероятность того, что к ячейке с состоянием мьютекса процессы обратятся одновременно и одновременно же попробуют его залочить. Поэтому в системе должен быть как минимум один аппаратный мьютекс, который будет закрывать доступ к программным мьютексам, причём закрывать серъёзно - т.е. останавливая все процессоры кроме одного (даже если обращается больше одного должен быть выбран один). Например путём вывода в некий порт программа будет говорить железяке, что она хочет поработать с одним из мьютексов (захватить или освободить), в этот момент железяка остановит все процессоры кроме просящего (либо первого из просящих), далее программа устанавливает (и идёт дальше либо запоминает что она должна локнуться) либо сбрасывает мьютекс и пишет в другой порт чтобы сигнализировать о том, что работа с мьютексами закончена - далее железяка отпускает все процессы, а просящий процесс либо висит на программном локе (ожидая когда программный мьютекс отпустят при этом ос может отдавать управление другим тредам на этом же процессоре), либо идёт дальше - в зависимости от результата лочки-анлочки программного мьютекса. Вобщем как-то так...
DI
MVI A,1
STA #FFFF
Это вызывает прерывание процессора-супервайзера. Далее процесс ожидает подтверждения - читает оттуда байт и ждёт когда младший бит станет равен нулю:
LOOP:
LDA #FFFF
RAR
JC LOOP
В момент подтверждения ожидающий процессор либо останавливается супервизором (если эта критическая секция уже локнута другим процессором либо процессор с более низким номером также хочет обратиться к критической секции), либо идёт дальше - локать или анлокать программный мьютекс.
Если интересующий нас мьютекс свободен (бит мьютекса сброшен) и процесс хочет его локнуть, то бит мьютекса взводится, а супервайзер уведомляется, что критическая секция покидается:
XRA A
STA #FFFF
EI
После этого супервайзер отпускает все остановленные процессоры, если таковые были.
Если интересующий нас мьютекс свободен, но процесс хочет его анлокнуть, то это ошибка, теоретически приводящая к трапу.
Если интересующий нас мьютекс локнут (бит мьютекса взведён) и процесс хочет его локнуть, то нужно ожидать анлока - для этого мы уведомляем супервизора что покидаем критическую секцию:
XRA A
STA #FFFF
EI
и висим в цикле ожидая сброса бита мьютекса, чтобы попытаться его локнуть когда он освободится (опять же зайдя в критическую секцию). При этом текущий процессор может переключить контекст, отдав вычислительные ресурсы другому процессу, ожидающему своего кванта времени.
Если интересующий нас мьютекс локнут и процесс хочет его отпустить (надо ли проверять то, что мьютекс отпускается именно тем процессом, который его локал?), то бит мьютекса сбрасывается и супервизор уведомляется о том, что критическая секция покинута:
XRA A
STA #FFFF
EI
P.S. Если мы решим повторить поведение стандартных мьютексов, то нам надо вести учёт того, какой процесс локнул мьютекс, чтобы разрешать анлокать только тому же самому процессу. Если анлокает другой процесс, то это должно приводить к трапу. Также иногда считается полезным (или удобным с точки зрения ленивых программистов?) разрешать локать мьютекс несколько раз при условии, что это делается из одного и того же процесса (nested mutexes).
P.P.S. Планировщик должен уметь распределять процессы по процессорам, переключая задачи с перегруженных процессоров на недогруженные. Также имеет смысл добавить приоритеты, в соответствии с которыми будут переключаться контексты и перераспределяться процессы. Важно что процессы, висящие на мьютексах, не получали квантов времени до того момента, пока нужный мьютекс не освободится.
P.P.P.S. Процессор номер 0 (супервайзер) кроме всего прочего может эмулировать протокол виртуального терминала VT52, читать-писать SD-карточку и/или работать с флопиком/винчестером, общаться с COM-портом, часами реального времени и т.д.
P.P.P.P.S. Аналогичное "рукопожатие" с супервизором должно происходить при ожидании ввода-вывода и при работе планировщика (точнее планировщиков, которых у нас будет четыре - по числу процессоров). Приоритеты процессов предполагаю задавать от 0 до 7 - чем больше, тем лучше (значение по умолчанию 1, а при нуле процесс встаёт намертво). Выбор максимального приоритета 7 обусловлен тем, что при наличии 32 страниц удобно затолкать в один байт код страницы где лежит процесс и приоритет процесса - в таком случае можно завести таблицу по числу возможных номеров процессов (максимальный номер может быть 255) где на каждый процесс будет отведён один байт (нулевой байт будет означать, что такой процесс несуществует) - процессы будут выбираться циклически и работать столько тактов подряд, сколько единиц содержится в приоритете соответствующего процесса (т.е. при 10 Гц прерывании это будет 0.1 сек минимум или 0.7 сек максимум, хотя может быть и дольше - если процессор долго сидит с запрещёнными прерываниями). Кроме того будет 4 байта в защищённой области в которых будут записаны номера процессов, работающих на каждом процессоре (являющихся активными в данный момент), чтобы планировщик процессора случайно не запустил процесс, который уже работает на другом процессоре.
Last edited by Shaos on 27 Aug 2012 22:29, edited 1 time in total.
-
Error404

- Maniac
- Posts: 269
- Joined: 05 Oct 2006 04:45
- Location: Moscow
Потому что CP/M нереентабельна, для мультитедовой, к примеру, модели (мы такую многозадачность делали на прерываниях в 90-х) перед точкой входа в CP/M приходилось ставить сериализатор, выстраивающий все параллельные обращения к API OC (call 5) в очередь последовательных вызовов.Shaos wrote: Наверное совместимость со старым софтом таки будет - предлагаю CP/M-80, но задачи CP/M-80 нельзя будет переключать - только запускать и гасить (хотя почему нельзя?).
Или сразу брать за эталон MP/M, а еще лучше - UZIX. Но MP/M будет проще в портировании.
Всем добра!
-
Shaos
- Admin
- Posts: 25092
- Joined: 08 Jan 2003 23:22
- Location: Silicon Valley
Ну я пока с CP/M-80 заморачиваться небуду - это так, планы на будущееError404 wrote:Потому что CP/M нереентабельна, для мультитедовой, к примеру, модели (мы такую многозадачность делали на прерываниях в 90-х) перед точкой входа в CP/M приходилось ставить сериализатор, выстраивающий все параллельные обращения к API OC (call 5) в очередь последовательных вызовов.Shaos wrote: Наверное совместимость со старым софтом таки будет - предлагаю CP/M-80, но задачи CP/M-80 нельзя будет переключать - только запускать и гасить (хотя почему нельзя?).
Или сразу брать за эталон MP/M, а еще лучше - UZIX. Но MP/M будет проще в портировании.
А вообще интересно было бы узнать о том кто как такое раньше делал - сохранились какие-то описания, схемки-диаграмки и т.д.?
