DDT (DG403+DG403=Ternary) synthesis and simulation tools
========================================================
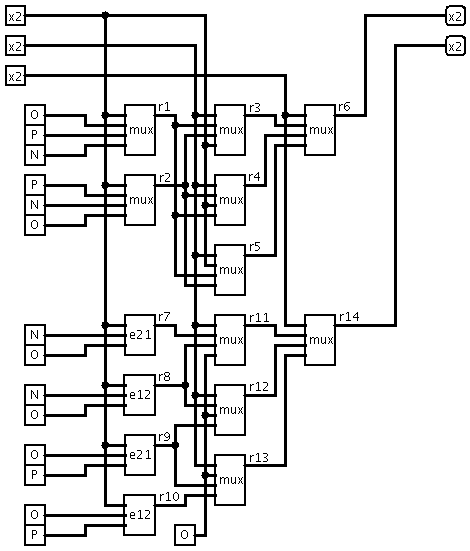
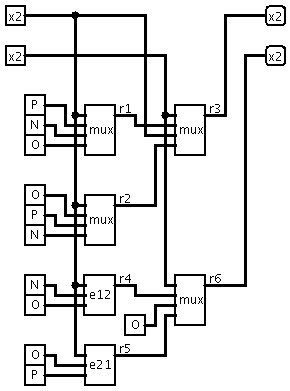
Main purpose of this package is automated design of ternary schematics,
based on analog switches DG403. Ternary signal may be connected to positive
voltage (+1 or P), negative voltage (-1 or N) or ground (0 or O). By
connecting logic voltage pins of DG403 (Vl and GND) to upper or lower
part of full range of analog voltage (between V- and V+) we may get two
different types of basic ternary elements - E12 (Vl=Ground, GND=Negative)
and E21 (Vl=Positive, GND=Ground). Each DG403 may have two E12 or two E21
elements. One E12 and one E21 may be connected together to create ternary
multiplexer (MUX) or universal ternary element. Also some special
functions may be constructed from E12 and E21, namely BLN (block
negative), BLP (block positive), RUP (rotate up), RDN (rotated down)
and NOT (ternary negation). Also there is basic element with memory
MEM (sample and hold circuit).
Source code ddt.h and ddt.c are set of functions for simulation of ternary
schematics programmatically in C-language.
DDTc is synthesis utility that may use command line argument as truth
table or as filename of DDT-file with truth table inside. Output of this
program is C-source that may be used for compiling simulation binary.
DDTp is permutating utility that is trying to find better solution
(in terms of DG403 number) by permutating inputs of given DDT-file and
calling DDTc for every combination with calculating of elements.
Code: Select all
all ternary functions of one argument:
NNN = N
NNO = SHD(x) = E21(x,N,O)
NNP = E21(x,N,P)
NON = MUX(x,N,O,N) = E12(x,N,E21(x,O,N))
NOO = BLP(x) = E12(x,N,O) // analog of reverse diode
NOP = x // or buffer MUX(x,N,O,P) = E12(x,N,E21(x,O,P))
NPN = MUX(x,N,P,N) = E12(x,N,E21(x,P,N))
NPO = MUX(x,N,P,O) = E12(x,N,E21(x,P,O))
NPP = E12(x,N,P)
ONN = NHI(x) = E12(x,O,N)
ONO = MUX(x,O,N,O) = E12(x,O,E21(x,N,O))
ONP = MUX(x,O,N,P) = E12(x,O,E21(x,N,P))
OON = E21(x,O,N)
OOO = O
OOP = BLN(x) = E21(x,O,P) // analog of forward diode
OPN = ROU(x) = MUX(x,O,P,N) = E12(x,O,E21(x,P,N))
OPO = MUX(x,O,P,O) = E12(x,O,E21(x,P,O))
OPP = SHU(x) = E12(x,O,P)
PNN = NTI(x) = E12(x,P,N)
PNO = ROD(x) = MUX(x,P,N,O) = E12(x,P,E21(x,N,O))
PNP = MUX(x,P,N,P) = E12(x,P,E21(x,N,P))
PON = NOT(x) = MUX(x,P,O,N) = E12(x,P,E21(x,O,N))
POO = E12(x,P,O)
POP = MUX(x,P,O,P) = E12(x,P,E21(x,O,P))
PPN = PTI(x) = E21(x,P,N)
PPO = PHI(x) = E21(x,P,O)
PPP = P