
Видеокарта, к несчастью, меня интересовать перестала, так и лежит не доделанная, даже схему в eagle нарисовать и выложить лень, извините.
Зато я всецело поглощен разработкой процессора (все-таки ввязался в это гиблое дело).
Идея отнюдь не утопична. Достаточно посетить этот сайт http://mycpu.thtec.org/www-mycpu-eu/ и потом полистать Homebuilt CPUs WebRing внизу страницы, чтобы узнать, что таких проектов было много, и большинство успешно воплощено в жизнь.
Основной принцип работы большинства этих CPU – управление микро-кодом, записанным в ПЛМ. На входы ПЛМ подается код операции, значения флагов и счетчик микрокоманд (микрокоанда – слово большой разрядности, каждый бит которого управляет некоторой простой отдельной частью ЦП, например, подает сигнал на вход OE\ некоторого регистра, управляя выдачей данных из него на внутреннюю шину и т. д.). Счетчик инкриементируется и таким образом с выхода ПЛМ последовательно подается набор микрокоманд необходимый для выполнения одной макрокоманды (той, чей код операции подан на входы ПЛМ)).
В качестве ПЛМ в этих проектах служит EPROM. Но я решил использовать для этих целей SRAM из-за малого (20 нс) времени доступа по сравнению с EPROM (100 нс), что позволяет добиться большего быстродействия. Сделать самопрограммирующийся при включении ЦП оказалось очень сложно, так что буду просто использовать батарейное питание SRAM хоть это и менее солидно.
АЛУ также строится на ПЛМ (в англ. варианте look-up tables), что гарантирует простоту и высокую скорость.
Это была теория. Сладкая. Теперь правда. Горькая.
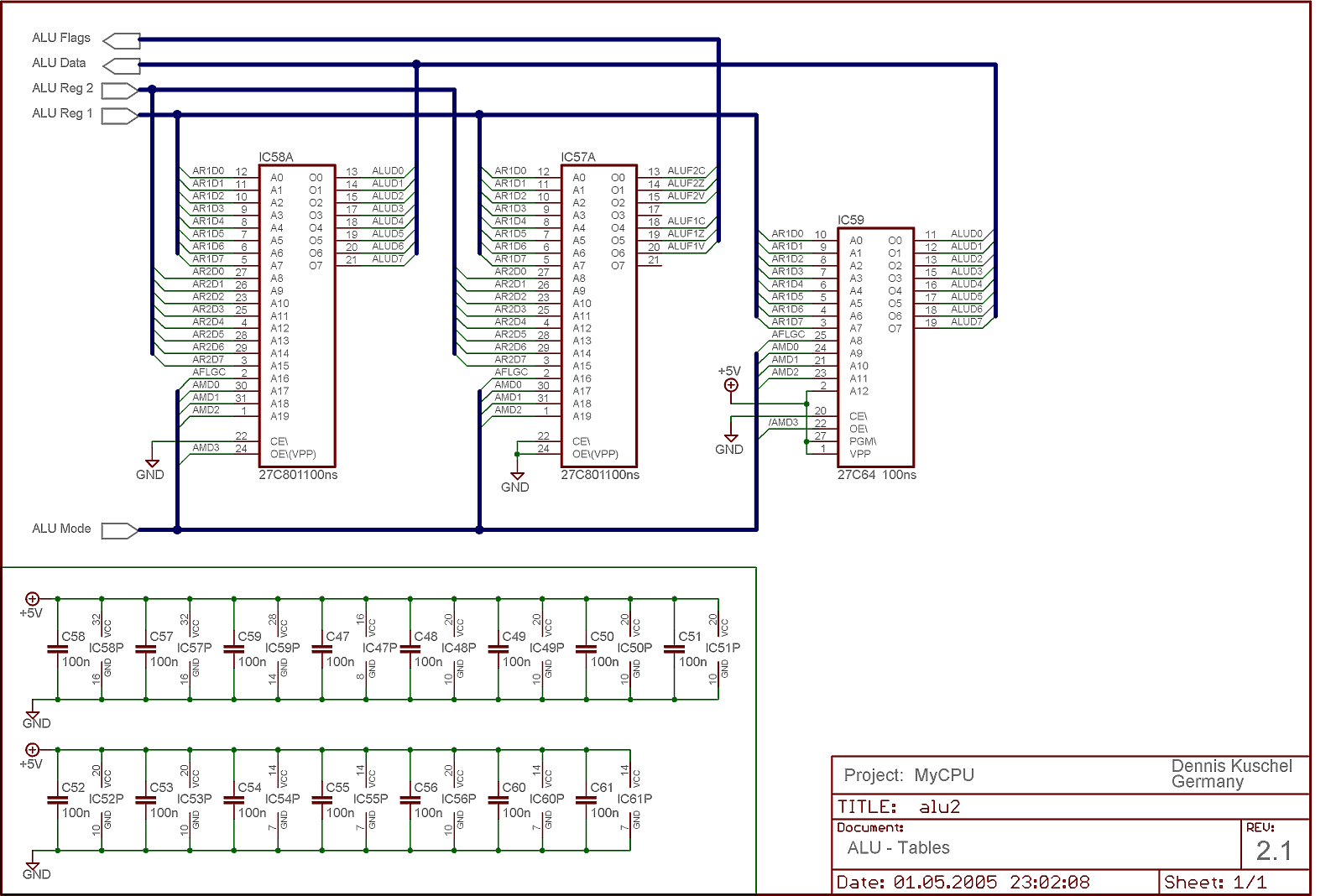
Это ПЛМ-ы АЛУ проекта MyCPU (регистры АЛУ и некоторая прочая логика на другой схеме, кому нужно все – зайдите на сайт и скачайте selfbuild guide).
АЛУ состоит из 2-х 8-ми мегабитных микросхем EPROM, в одной результаты бинарных операций, в другой флаги, и еще одной 8-ми килобайтной -- содержатся результаты унарных операций. У этих микросхем по 20 адресных входов. 2 х 8 – операнды, 3 – код бинарной операции, и один вход для флага переноса CF.
Я располагаю микросхемами SRAM xxC256 у которых лишь 14 адресных входов, чего не хватает даже для двух операндов.
Выход в каскадировании. Сделать 8-ми разрядное АЛУ из двух 4-разрядных. На входы первого 4р. АЛУ подаются младшие 4 бита каждого операнда, на входы второго – старшие. Флаги C и Z результата первого АЛУ заводятся во второе. Общая задержка «операнд-стабильный результат» равна суме задержек двух микросхем памяти. Такое АЛУ, к сожалению, не может умножать и делить.
Вот моя схема:

ID_BUS — internal data bus внутренняя шина данных ЦП
CD_BUS – command data bus шина по которой передается операнд содержащийся в коде команды.
ALU_CMD – ALU command код операции АЛУ и управляющие сигналы.
Загрузка 2-го операнда осуществляется через «прозрачную» защелку 1-го, для уменьшения нагрузки на шину.
(Нашел в схеме незначительные ошибки, но перезагружаться в винду и исправлять -- не хочется)
К несчастью эта схема нуждается в переработке, т. к. она не может осуществлять сдвиги вправо. Однако каскадирование позволяет собрать и 16-разрядное АЛУ, чего нельзя сделать просто заведя все операнды и код в одну EPROM как это было сделано в MyCPU. Иначе нужна ROM на 64 ГБ
Теперь я думаю, а не сделать ли 16-bit CPU? Это было бы круто! Но к несчастью сопряжено с рядом трудностей.
Сейчас важно понять в каком направлении идти. Вот и хотел бы вас по этому поводу спросить. Кто что думает?
Многие проблемы касательно выравнивания команд я уже решил. Но самые большие заморочки с программной архитектурой. Какой должен быть набор команд?
В 8-ми битных ЦП во всех арифметических командах один неявно заданный операнд – аккумулятор. Это экономит коды команд. А в x86 можно написать
Code: Select all
add bx, cxCode: Select all
add bl, bh256 кодов операций для этого не хватит.
Регистры я храню во внутреннем ОЗУ, так что их число ограничивается лишь количеством кодов...
Делать ли регистры делимыми на независимые старшую и младшую часть?





